 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Twins Talk & Alternative Calculations
Paper and Code

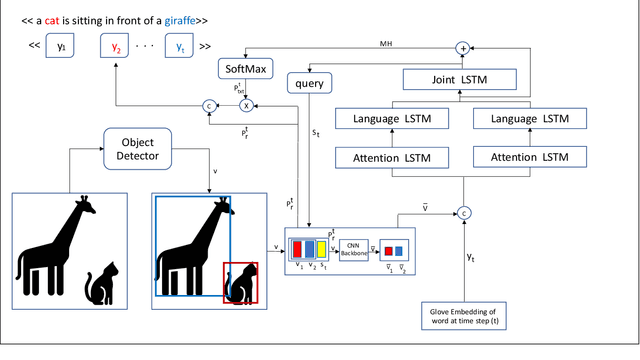
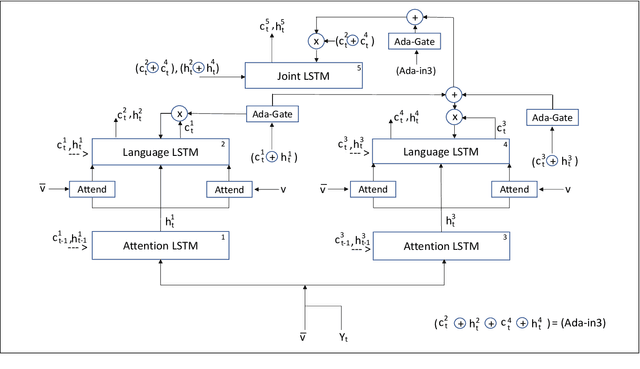

Inspired by how the human brain employs a higher number of neural pathways when describing a highly focused subject, we show that deep attentive models used for the main vision-language task of image captioning, could be extended to achieve better performance. Image captioning bridges a gap between computer vision and natural language processing. Automated image captioning is used as a tool to eliminate the need for human agent for creating descriptive captions for unseen images.Automated image captioning is challenging and yet interesting. One reason is that AI based systems capable of generating sentences that describe an input image could be used in a wide variety of tasks beyond generating captions for unseen images found on web or uploaded to social media. For example, in biology and medical sciences, these systems could provide researchers and physicians with a brief linguistic description of relevant images, potentially expediting their work.