 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering Dynamic Web Usage Data
Jan 04, 2012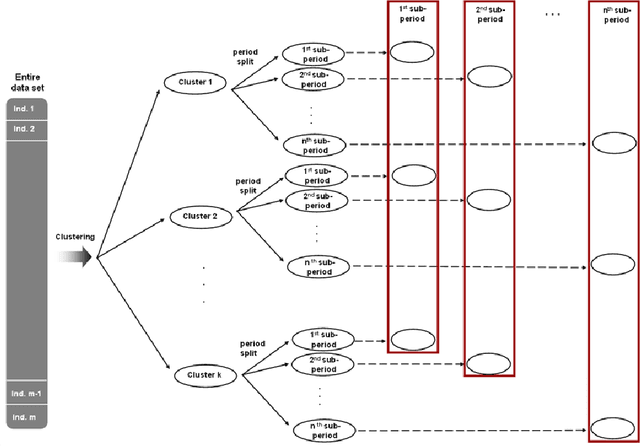

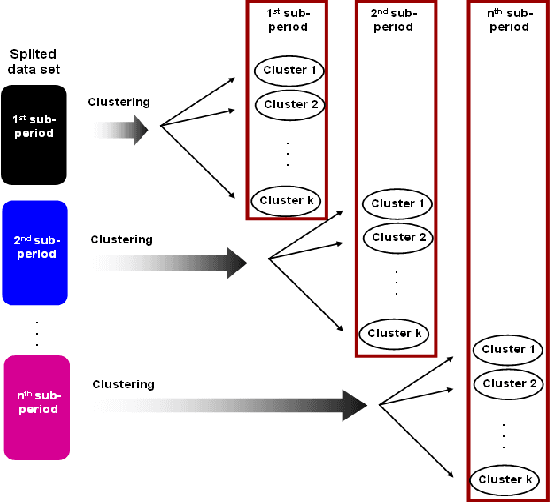
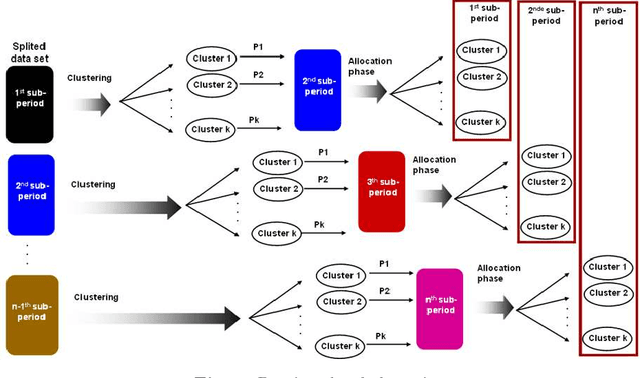
Most classification methods are based on the assumption that data conforms to a stationary distribution. The machine learning domain currently suffers from a lack of classification techniques that are able to detect the occurrence of a change in the underlying data distribution. Ignoring possible changes in the underlying concept, also known as concept drift, may degrade the performance of the classification model. Often these changes make the model inconsistent and regular updatings become necessary. Taking the temporal dimension into account during the analysis of Web usage data is a necessity, since the way a site is visited may indeed evolve due to modifications in the structure and content of the site, or even due to changes in the behavior of certain user groups. One solution to this problem, proposed in this article, is to update models using summaries obtained by means of an evolutionary approach based on an intelligent clustering approach. We carry out various clustering strategies that are applied on time sub-periods. To validate our approach we apply two external evaluation criteria which compare different partitions from the same data set. Our experiments show that the proposed approach is efficient to detect the occurrence of changes.
Constrained variable clustering and the best basis problem in functional data analysis
Jan 04, 2012

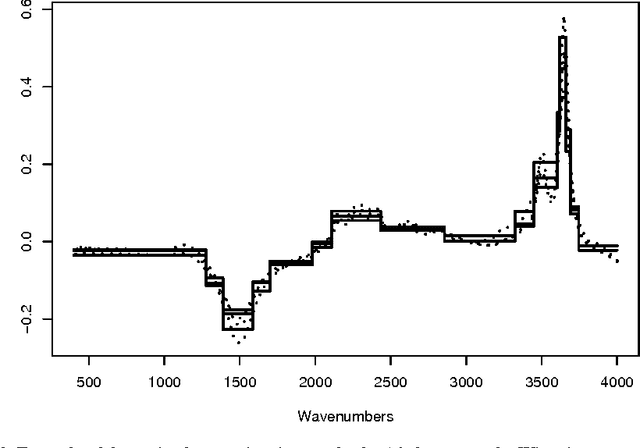
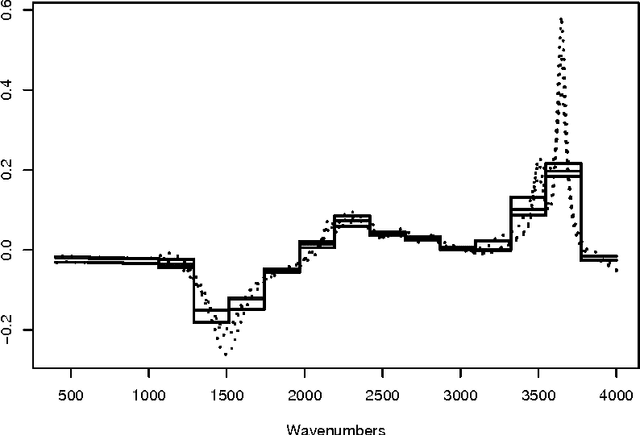
Functional data analysis involves data described by regular functions rather than by a finite number of real valued variables. While some robust data analysis methods can be applied directly to the very high dimensional vectors obtained from a fine grid sampling of functional data, all methods benefit from a prior simplification of the functions that reduces the redundancy induced by the regularity. In this paper we propose to use a clustering approach that targets variables rather than individual to design a piecewise constant representation of a set of functions. The contiguity constraint induced by the functional nature of the variables allows a polynomial complexity algorithm to give the optimal solution.
Exploratory Analysis of Functional Data via Clustering and Optimal Segmentation
Apr 03, 2010

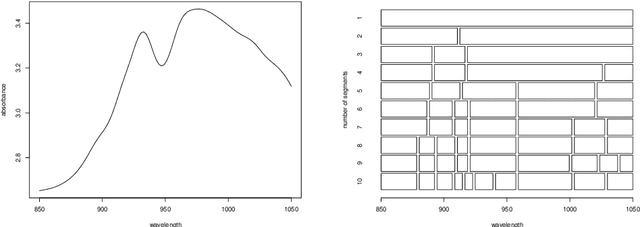
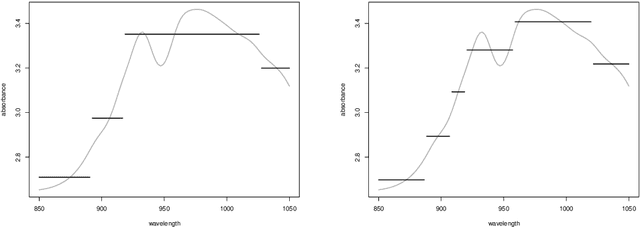
We propose in this paper an exploratory analysis algorithm for functional data. The method partitions a set of functions into $K$ clusters and represents each cluster by a simple prototype (e.g., piecewise constant). The total number of segments in the prototypes, $P$, is chosen by the user and optimally distributed among the clusters via two dynamic programming algorithms. The practical relevance of the method is shown on two real world datasets.
Une adaptation des cartes auto-organisatrices pour des données décrites par un tableau de dissimilarités
Sep 22, 2007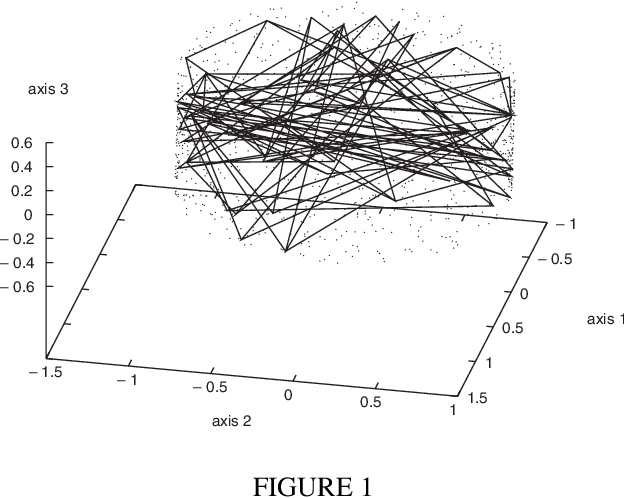
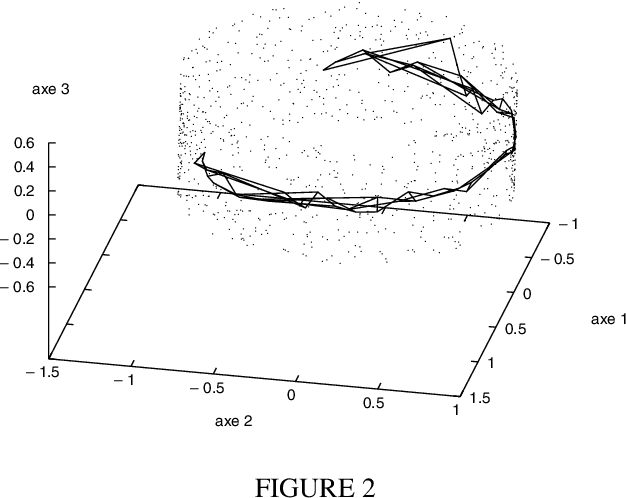
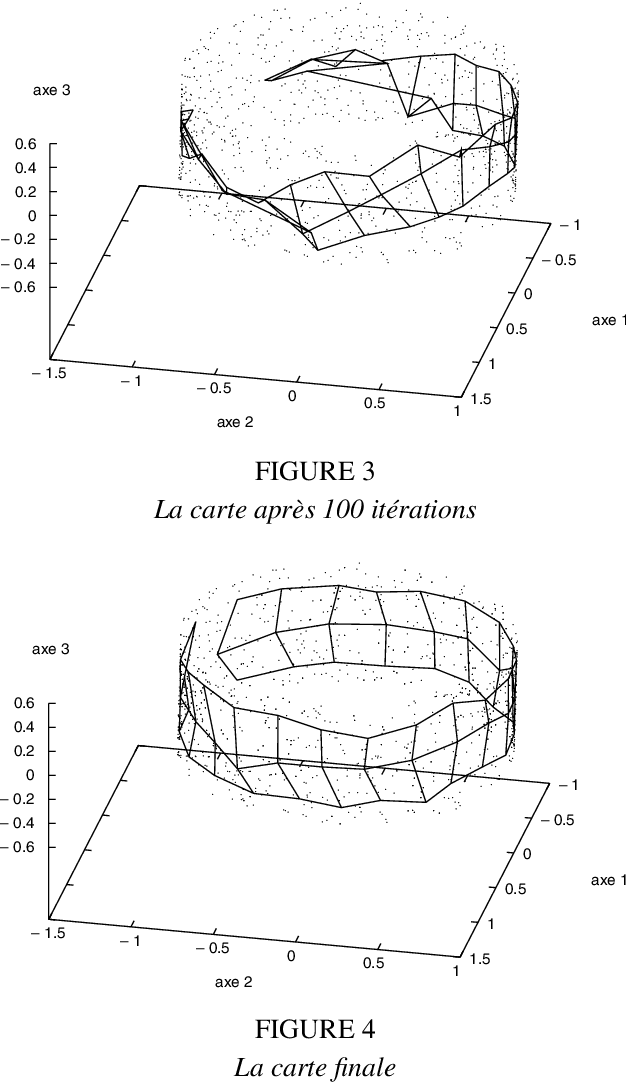
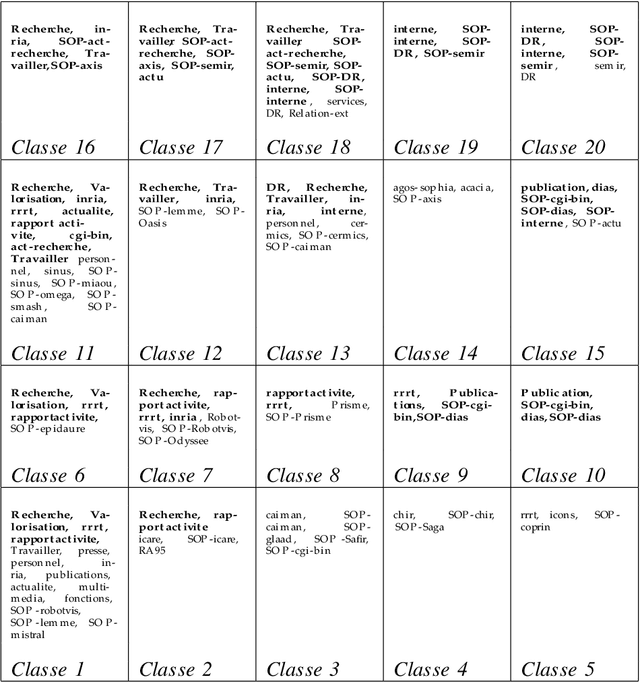
Many data analysis methods cannot be applied to data that are not represented by a fixed number of real values, whereas most of real world observations are not readily available in such a format. Vector based data analysis methods have therefore to be adapted in order to be used with non standard complex data. A flexible and general solution for this adaptation is to use a (dis)similarity measure. Indeed, thanks to expert knowledge on the studied data, it is generally possible to define a measure that can be used to make pairwise comparison between observations. General data analysis methods are then obtained by adapting existing methods to (dis)similarity matrices. In this article, we propose an adaptation of Kohonen's Self Organizing Map (SOM) to (dis)similarity data. The proposed algorithm is an adapted version of the vector based batch SOM. The method is validated on real world data: we provide an analysis of the usage patterns of the web site of the Institut National de Recherche en Informatique et Automatique, constructed thanks to web log mining method.