 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
SCORE: Soft Label Compression-Centric Dataset Condensation via Coding Rate Optimization
Mar 18, 2025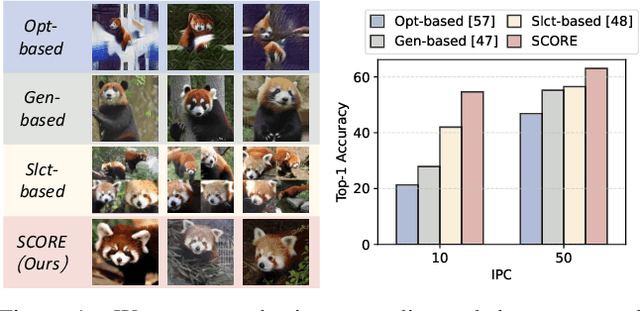


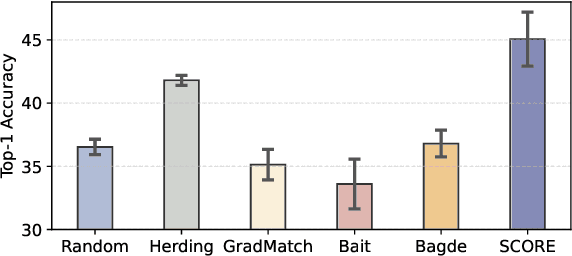
Dataset Condensation (DC) aims to obtain a condensed dataset that allows models trained on the condensed dataset to achieve performance comparable to those trained on the full dataset. Recent DC approaches increasingly focus on encoding knowledge into realistic images with soft labeling, for their scalability to ImageNet-scale datasets and strong capability of cross-domain generalization. However, this strong performance comes at a substantial storage cost which could significantly exceed the storage cost of the original dataset. We argue that the three key properties to alleviate this performance-storage dilemma are informativeness, discriminativeness, and compressibility of the condensed data. Towards this end, this paper proposes a \textbf{S}oft label compression-centric dataset condensation framework using \textbf{CO}ding \textbf{R}at\textbf{E} (SCORE). SCORE formulates dataset condensation as a min-max optimization problem, which aims to balance the three key properties from an information-theoretic perspective. In particular, we theoretically demonstrate that our coding rate-inspired objective function is submodular, and its optimization naturally enforces low-rank structure in the soft label set corresponding to each condensed data. Extensive experiments on large-scale datasets, including ImageNet-1K and Tiny-ImageNet, demonstrate that SCORE outperforms existing methods in most cases. Even with 30$\times$ compression of soft labels, performance decreases by only 5.5\% and 2.7\% for ImageNet-1K with IPC 10 and 50, respectively. Code will be released upon paper acceptance.