 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSGANv2: Improved Subject Agnostic Face Swapping and Reenactment
Feb 25, 2022

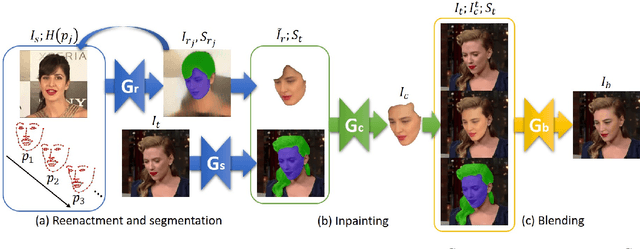

We present Face Swapping GAN (FSGAN) for face swapping and reenactment. Unlike previous work, we offer a subject agnostic swapping scheme that can be applied to pairs of faces without requiring training on those faces. We derive a novel iterative deep learning--based approach for face reenactment which adjusts significant pose and expression variations that can be applied to a single image or a video sequence. For video sequences, we introduce a continuous interpolation of the face views based on reenactment, Delaunay Triangulation, and barycentric coordinates. Occluded face regions are handled by a face completion network. Finally, we use a face blending network for seamless blending of the two faces while preserving the target skin color and lighting conditions. This network uses a novel Poisson blending loss combining Poisson optimization with a perceptual loss. We compare our approach to existing state-of-the-art systems and show our results to be both qualitatively and quantitatively superior. This work describes extensions of the FSGAN method, proposed in an earlier conference version of our work, as well as additional experiments and results.
* arXiv admin note: text overlap with arXiv:1908.05932
HyperSeg: Patch-wise Hypernetwork for Real-time Semantic Segmentation
Dec 21, 2020

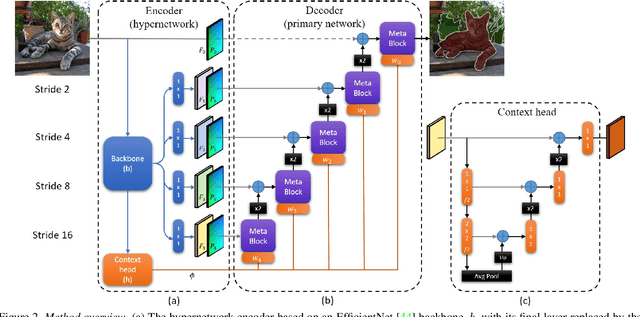
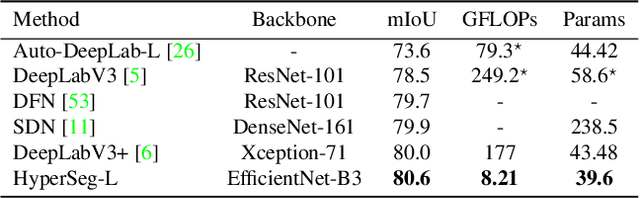
We present a novel, real-time, semantic segmentation network in which the encoder both encodes and generates the parameters (weights) of the decoder. Furthermore, to allow maximal adaptivity, the weights at each decoder block vary spatially. For this purpose, we design a new type of hypernetwork, composed of a nested U-Net for drawing higher level context features, a multi-headed weight generating module which generates the weights of each block in the decoder immediately before they are consumed, for efficient memory utilization, and a primary network that is composed of novel dynamic patch-wise convolutions. Despite the usage of less-conventional blocks, our architecture obtains real-time performance. In terms of the runtime vs. accuracy trade-off, we surpass state of the art (SotA) results on popular semantic segmentation benchmarks: PASCAL VOC 2012 (val. set) and real-time semantic segmentation on Cityscapes, and CamVid.
DeepFake Detection Based on the Discrepancy Between the Face and its Context
Aug 27, 2020


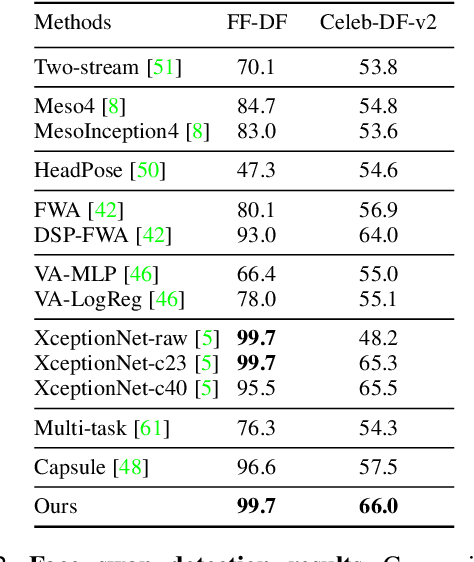
We propose a method for detecting face swapping and other identity manipulations in single images. Face swapping methods, such as DeepFake, manipulate the face region, aiming to adjust the face to the appearance of its context, while leaving the context unchanged. We show that this modus operandi produces discrepancies between the two regions. These discrepancies offer exploitable telltale signs of manipulation. Our approach involves two networks: (i) a face identification network that considers the face region bounded by a tight semantic segmentation, and (ii) a context recognition network that considers the face context (e.g., hair, ears, neck). We describe a method which uses the recognition signals from our two networks to detect such discrepancies, providing a complementary detection signal that improves conventional real vs. fake classifiers commonly used for detecting fake images. Our method achieves state of the art results on the FaceForensics++, Celeb-DF-v2, and DFDC benchmarks for face manipulation detection, and even generalizes to detect fakes produced by unseen methods.
FSGAN: Subject Agnostic Face Swapping and Reenactment
Aug 16, 2019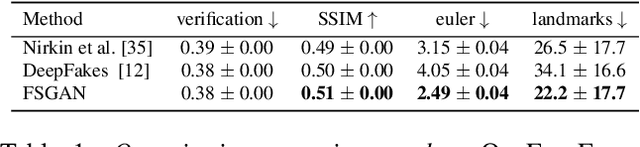



We present Face Swapping GAN (FSGAN) for face swapping and reenactment. Unlike previous work, FSGAN is subject agnostic and can be applied to pairs of faces without requiring training on those faces. To this end, we describe a number of technical contributions. We derive a novel recurrent neural network (RNN)-based approach for face reenactment which adjusts for both pose and expression variations and can be applied to a single image or a video sequence. For video sequences, we introduce continuous interpolation of the face views based on reenactment, Delaunay Triangulation, and barycentric coordinates. Occluded face regions are handled by a face completion network. Finally, we use a face blending network for seamless blending of the two faces while preserving target skin color and lighting conditions. This network uses a novel Poisson blending loss which combines Poisson optimization with perceptual loss. We compare our approach to existing state-of-the-art systems and show our results to be both qualitatively and quantitatively superior.
Extreme 3D Face Reconstruction: Seeing Through Occlusions
Mar 29, 2018
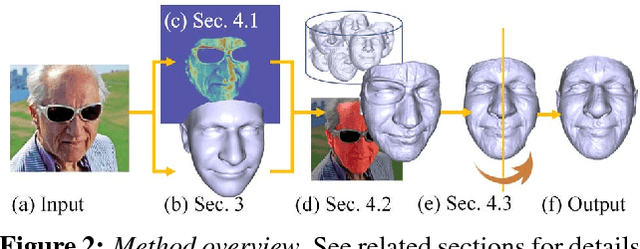


Existing single view, 3D face reconstruction methods can produce beautifully detailed 3D results, but typically only for near frontal, unobstructed viewpoints. We describe a system designed to provide detailed 3D reconstructions of faces viewed under extreme conditions, out of plane rotations, and occlusions. Motivated by the concept of bump mapping, we propose a layered approach which decouples estimation of a global shape from its mid-level details (e.g., wrinkles). We estimate a coarse 3D face shape which acts as a foundation and then separately layer this foundation with details represented by a bump map. We show how a deep convolutional encoder-decoder can be used to estimate such bump maps. We further show how this approach naturally extends to generate plausible details for occluded facial regions. We test our approach and its components extensively, quantitatively demonstrating the invariance of our estimated facial details. We further provide numerous qualitative examples showing that our method produces detailed 3D face shapes in viewing conditions where existing state of the art often break down.
On Face Segmentation, Face Swapping, and Face Perception
Apr 22, 2017

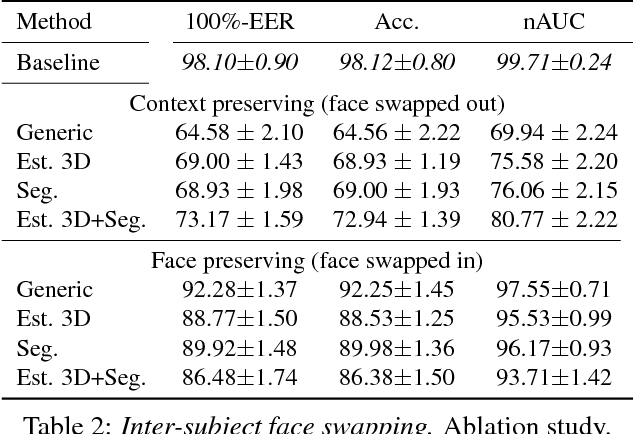

We show that even when face images are unconstrained and arbitrarily paired, face swapping between them is actually quite simple. To this end, we make the following contributions. (a) Instead of tailoring systems for face segmentation, as others previously proposed, we show that a standard fully convolutional network (FCN) can achieve remarkably fast and accurate segmentations, provided that it is trained on a rich enough example set. For this purpose, we describe novel data collection and generation routines which provide challenging segmented face examples. (b) We use our segmentations to enable robust face swapping under unprecedented conditions. (c) Unlike previous work, our swapping is robust enough to allow for extensive quantitative tests. To this end, we use the Labeled Faces in the Wild (LFW) benchmark and measure the effect of intra- and inter-subject face swapping on recognition. We show that our intra-subject swapped faces remain as recognizable as their sources, testifying to the effectiveness of our method. In line with well known perceptual studies, we show that better face swapping produces less recognizable inter-subject results. This is the first time this effect was quantitatively demonstrated for machine vision systems.