 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP2Net: A Post-Processing Network for Refining Semantic Segmentation of LiDAR Point Cloud based on Consistency of Consecutive Frames
Dec 01, 2022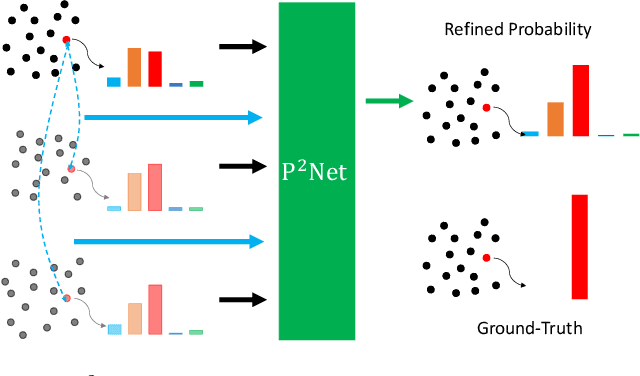
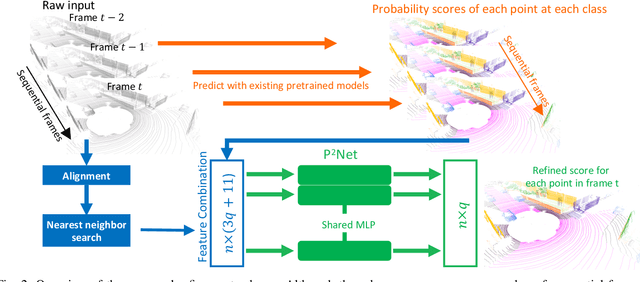
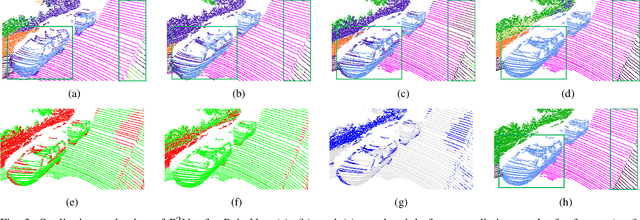
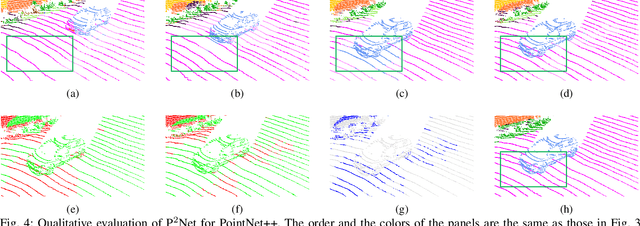
We present a lightweight post-processing method to refine the semantic segmentation results of point cloud sequences. Most existing methods usually segment frame by frame and encounter the inherent ambiguity of the problem: based on a measurement in a single frame, labels are sometimes difficult to predict even for humans. To remedy this problem, we propose to explicitly train a network to refine these results predicted by an existing segmentation method. The network, which we call the P2Net, learns the consistency constraints between coincident points from consecutive frames after registration. We evaluate the proposed post-processing method both qualitatively and quantitatively on the SemanticKITTI dataset that consists of real outdoor scenes. The effectiveness of the proposed method is validated by comparing the results predicted by two representative networks with and without the refinement by the post-processing network. Specifically, qualitative visualization validates the key idea that labels of the points that are difficult to predict can be corrected with P2Net. Quantitatively, overall mIoU is improved from 10.5% to 11.7% for PointNet [1] and from 10.8% to 15.9% for PointNet++ [2].