 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic Face Reenactment via Self-Supervised Disentangling of Identity and Pose
Mar 29, 2020
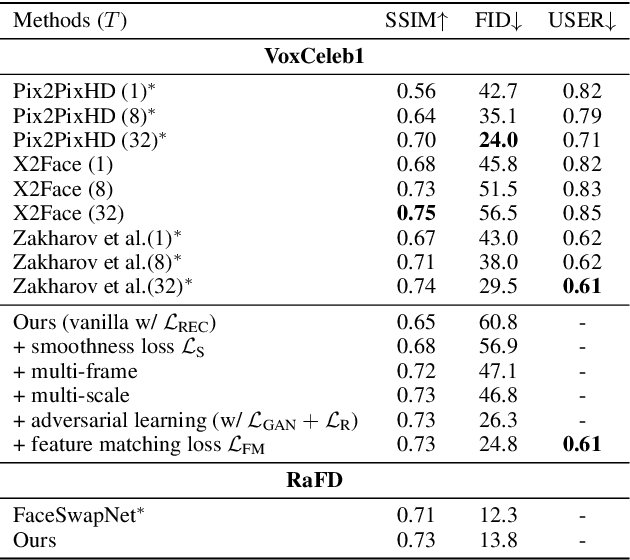
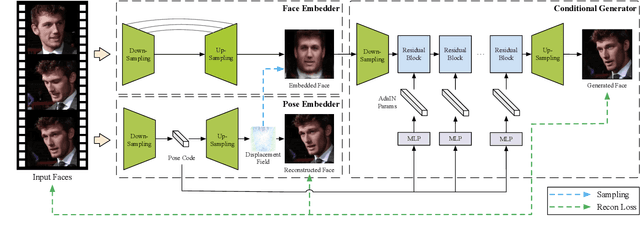
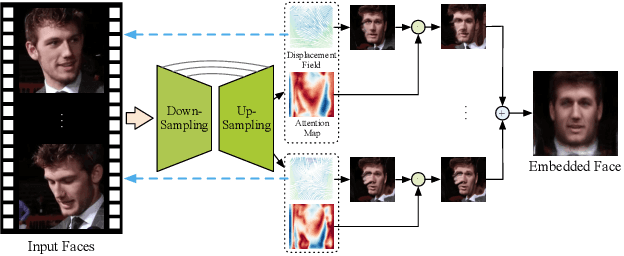
Recent works have shown how realistic talking face images can be obtained under the supervision of geometry guidance, e.g., facial landmark or boundary. To alleviate the demand for manual annotations, in this paper, we propose a novel self-supervised hybrid model (DAE-GAN) that learns how to reenact face naturally given large amounts of unlabeled videos. Our approach combines two deforming autoencoders with the latest advances in the conditional generation. On the one hand, we adopt the deforming autoencoder to disentangle identity and pose representations. A strong prior in talking face videos is that each frame can be encoded as two parts: one for video-specific identity and the other for various poses. Inspired by that, we utilize a multi-frame deforming autoencoder to learn a pose-invariant embedded face for each video. Meanwhile, a multi-scale deforming autoencoder is proposed to extract pose-related information for each frame. On the other hand, the conditional generator allows for enhancing fine details and overall reality. It leverages the disentangled features to generate photo-realistic and pose-alike face images. We evaluate our model on VoxCeleb1 and RaFD dataset. Experiment results demonstrate the superior quality of reenacted images and the flexibility of transferring facial movements between identities.
FaceSwapNet: Landmark Guided Many-to-Many Face Reenactment
May 28, 2019
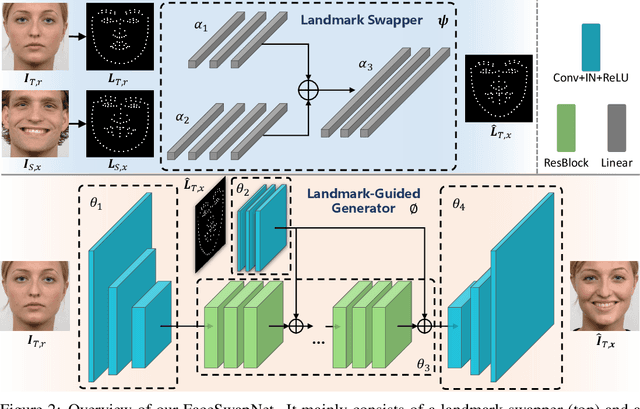
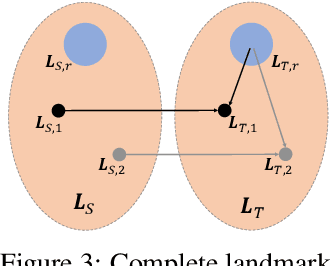
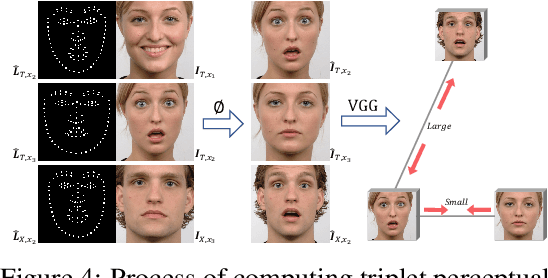
Recent face reenactment studies have achieved remarkable success either between two identities or in the many-to-one task. However, existing methods have limited scalability when the target person is not a predefined specific identity. To address this limitation, we present a novel many-to-many face reenactment framework, named FaceSwapNet, which allows transferring facial expressions and movements from one source face to arbitrary targets. Our proposed approach is composed of two main modules: the landmark swapper and the landmark-guided generator. Instead of maintaining independent models for each pair of person, the former module uses two encoders and one decoder to adapt anyone's face landmark to target persons. Using the neutral expression of the target person as a reference image, the latter module leverages geometry information from the swapped landmark to generate photo-realistic and emotion-alike images. In addition, a novel triplet perceptual loss is proposed to force the generator to learn geometry and appearance information simultaneously. We evaluate our model on RaFD dataset and the results demonstrate the superior quality of reenacted images as well as the flexibility of transferring facial movements between identities.