 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic Face Reenactment via Self-Supervised Disentangling of Identity and Pose
Paper and Code
Mar 29, 2020
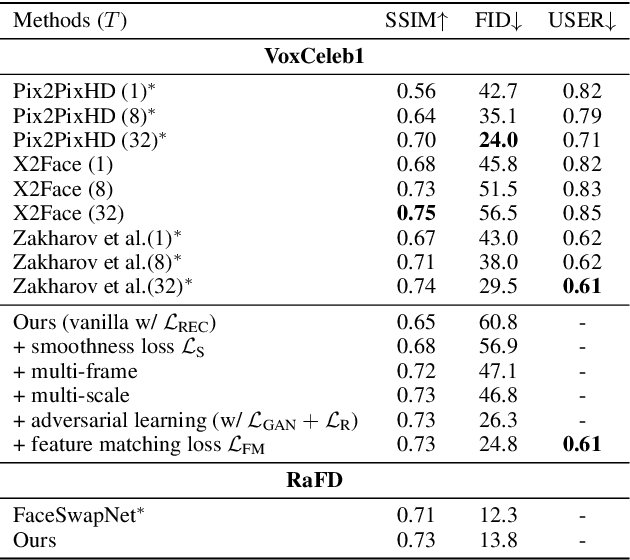
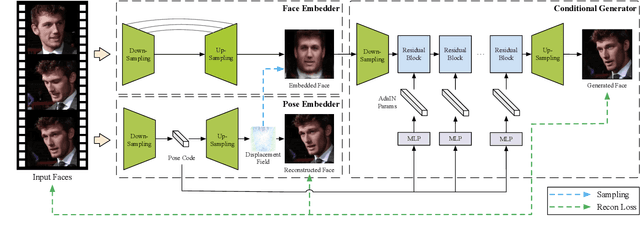
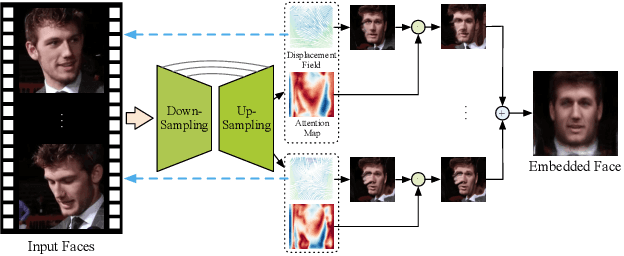
Recent works have shown how realistic talking face images can be obtained under the supervision of geometry guidance, e.g., facial landmark or boundary. To alleviate the demand for manual annotations, in this paper, we propose a novel self-supervised hybrid model (DAE-GAN) that learns how to reenact face naturally given large amounts of unlabeled videos. Our approach combines two deforming autoencoders with the latest advances in the conditional generation. On the one hand, we adopt the deforming autoencoder to disentangle identity and pose representations. A strong prior in talking face videos is that each frame can be encoded as two parts: one for video-specific identity and the other for various poses. Inspired by that, we utilize a multi-frame deforming autoencoder to learn a pose-invariant embedded face for each video. Meanwhile, a multi-scale deforming autoencoder is proposed to extract pose-related information for each frame. On the other hand, the conditional generator allows for enhancing fine details and overall reality. It leverages the disentangled features to generate photo-realistic and pose-alike face images. We evaluate our model on VoxCeleb1 and RaFD dataset. Experiment results demonstrate the superior quality of reenacted images and the flexibility of transferring facial movements between identities.