 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper-Universal Regularized Newton Method
Aug 11, 2022
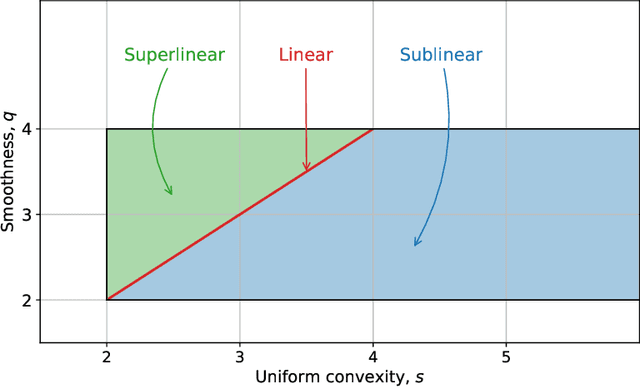

We analyze the performance of a variant of Newton method with quadratic regularization for solving composite convex minimization problems. At each step of our method, we choose regularization parameter proportional to a certain power of the gradient norm at the current point. We introduce a family of problem classes characterized by H\"older continuity of either the second or third derivative. Then we present the method with a simple adaptive search procedure allowing an automatic adjustment to the problem class with the best global complexity bounds, without knowing specific parameters of the problem. In particular, for the class of functions with Lipschitz continuous third derivative, we get the global $O(1/k^3)$ rate, which was previously attributed to third-order tensor methods. When the objective function is uniformly convex, we justify an automatic acceleration of our scheme, resulting in a faster global rate and local superlinear convergence. The switching between the different rates (sublinear, linear, and superlinear) is automatic. Again, for that, no a priori knowledge of parameters is needed.
Stochastic Subspace Cubic Newton Method
Feb 21, 2020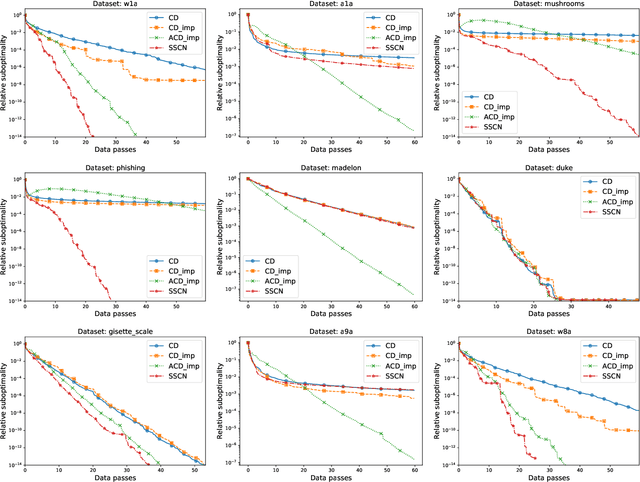
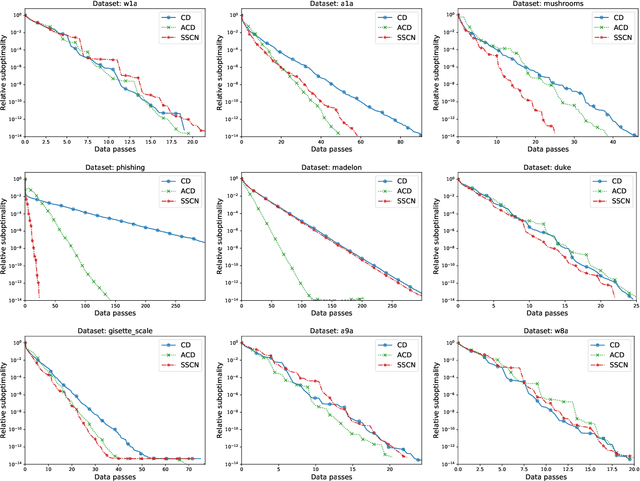
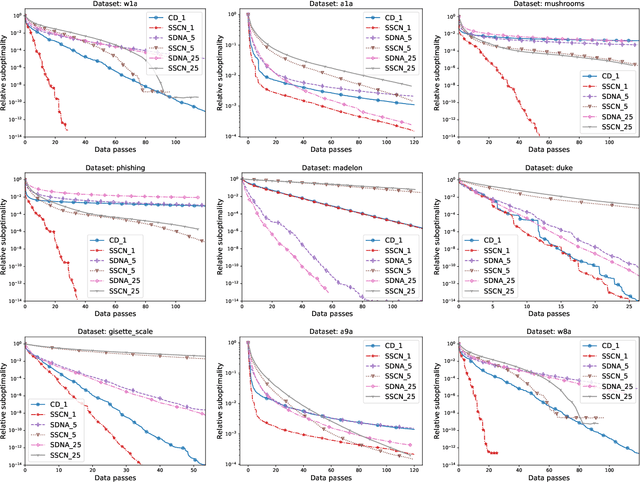
In this paper, we propose a new randomized second-order optimization algorithm---Stochastic Subspace Cubic Newton (SSCN)---for minimizing a high dimensional convex function $f$. Our method can be seen both as a {\em stochastic} extension of the cubically-regularized Newton method of Nesterov and Polyak (2006), and a {\em second-order} enhancement of stochastic subspace descent of Kozak et al. (2019). We prove that as we vary the minibatch size, the global convergence rate of SSCN interpolates between the rate of stochastic coordinate descent (CD) and the rate of cubic regularized Newton, thus giving new insights into the connection between first and second-order methods. Remarkably, the local convergence rate of SSCN matches the rate of stochastic subspace descent applied to the problem of minimizing the quadratic function $\frac12 (x-x^*)^\top \nabla^2f(x^*)(x-x^*)$, where $x^*$ is the minimizer of $f$, and hence depends on the properties of $f$ at the optimum only. Our numerical experiments show that SSCN outperforms non-accelerated first-order CD algorithms while being competitive to their accelerated variants.