 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Text Corpus Exploration with Post Hoc Explanations and Comparative Design
Jun 14, 2024
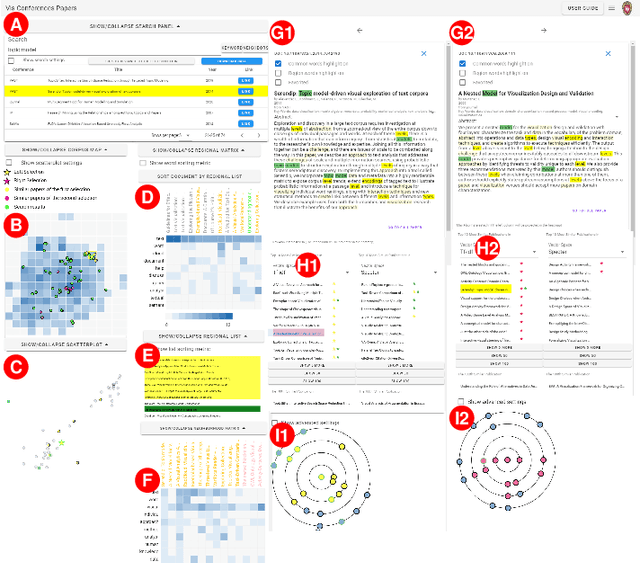
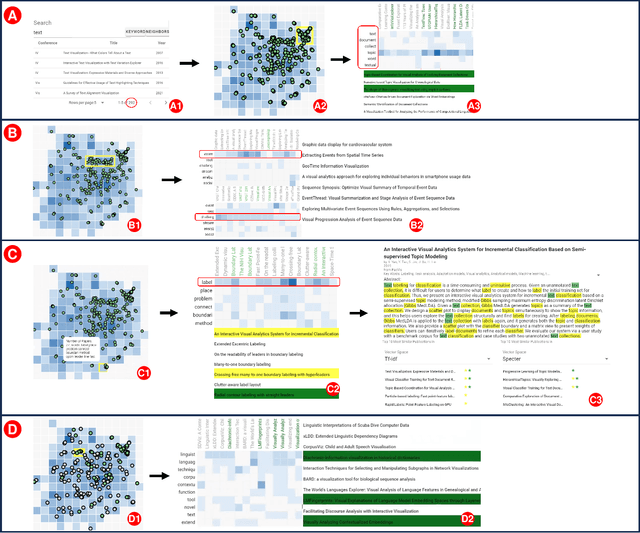

Text corpus exploration (TCE) spans the range of exploratory search tasks: it goes beyond simple retrieval to include item discovery and learning about the corpus and topic. Systems support TCE with tools such as similarity-based recommendations and embedding-based spatial maps. However, these tools address specific tasks; current systems lack the flexibility to support the range of tasks encountered in practice and the iterative, multiscale, workflows users employ. In this paper, we provide methods that enhance TCE tools with post hoc explanations and multiscale, comparative designs to provide flexible support for user needs. We introduce salience functions as a mechanism to provide post hoc explanations of similarity, recommendations, and spatial placement. This post hoc strategy allows our approach to complement a variety of underlying algorithms; the salience functions provide both exemplar- and feature-based explanations at scales ranging from individual documents through to the entire corpus. These explanations are incorporated into a set of views that operate at multiple scales. The views use design elements that explicitly support comparison to enable flexible integration. Together, these form an approach that provides a flexible toolset that can address a range of tasks. We demonstrate our approach in a prototype system that enables the exploration of corpora of paper abstracts and newspaper archives. Examples illustrate how our approach enables the system to flexibly support a wide range of tasks and workflows that emerge in user scenarios. A user study confirms that researchers are able to use our system to achieve a variety of tasks.
A Machine Learning Framework for Data Ingestion in Document Images
Feb 11, 2020

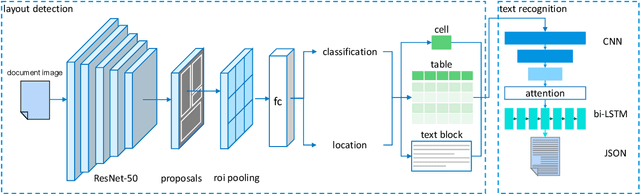

Paper documents are widely used as an irreplaceable channel of information in many fields, especially in financial industry, fostering a great amount of demand for systems which can convert document images into structured data representations. In this paper, we present a machine learning framework for data ingestion in document images, which processes the images uploaded by users and return fine-grained data in JSON format. Details of model architectures, design strategies, distinctions with existing solutions and lessons learned during development are elaborated. We conduct abundant experiments on both synthetic and real-world data in State Street. The experimental results indicate the effectiveness and efficiency of our methods.