Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine Learning Framework for Data Ingestion in Document Images
Paper and Code
Feb 11, 2020

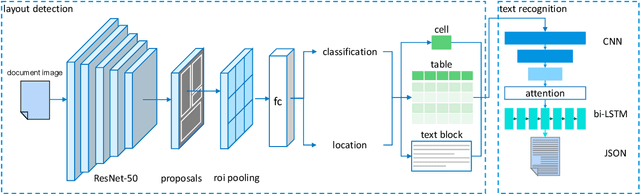

Paper documents are widely used as an irreplaceable channel of information in many fields, especially in financial industry, fostering a great amount of demand for systems which can convert document images into structured data representations. In this paper, we present a machine learning framework for data ingestion in document images, which processes the images uploaded by users and return fine-grained data in JSON format. Details of model architectures, design strategies, distinctions with existing solutions and lessons learned during development are elaborated. We conduct abundant experiments on both synthetic and real-world data in State Street. The experimental results indicate the effectiveness and efficiency of our methods.
View paper on