 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAR-Former V2: Rethinking Transformer for Universal Neural Network Representation Learning
Jun 19, 2023



As more deep learning models are being applied in real-world applications, there is a growing need for modeling and learning the representations of neural networks themselves. An efficient representation can be used to predict target attributes of networks without the need for actual training and deployment procedures, facilitating efficient network deployment and design. Recently, inspired by the success of Transformer, some Transformer-based representation learning frameworks have been proposed and achieved promising performance in handling cell-structured models. However, graph neural network (GNN) based approaches still dominate the field of learning representation for the entire network. In this paper, we revisit Transformer and compare it with GNN to analyse their different architecture characteristics. We then propose a modified Transformer-based universal neural network representation learning model NAR-Former V2. It can learn efficient representations from both cell-structured networks and entire networks. Specifically, we first take the network as a graph and design a straightforward tokenizer to encode the network into a sequence. Then, we incorporate the inductive representation learning capability of GNN into Transformer, enabling Transformer to generalize better when encountering unseen architecture. Additionally, we introduce a series of simple yet effective modifications to enhance the ability of the Transformer in learning representation from graph structures. Our proposed method surpasses the GNN-based method NNLP by a significant margin in latency estimation on the NNLQP dataset. Furthermore, regarding accuracy prediction on the NASBench101 and NASBench201 datasets, our method achieves highly comparable performance to other state-of-the-art methods.
NAR-Former: Neural Architecture Representation Learning towards Holistic Attributes Prediction
Nov 15, 2022



With the wide and deep adoption of deep learning models in real applications, there is an increasing need to model and learn the representations of the neural networks themselves. These models can be used to estimate attributes of different neural network architectures such as the accuracy and latency, without running the actual training or inference tasks. In this paper, we propose a neural architecture representation model that can be used to estimate these attributes holistically. Specifically, we first propose a simple and effective tokenizer to encode both the operation and topology information of a neural network into a single sequence. Then, we design a multi-stage fusion transformer to build a compact vector representation from the converted sequence. For efficient model training, we further propose an information flow consistency augmentation and correspondingly design an architecture consistency loss, which brings more benefits with less augmentation samples compared with previous random augmentation strategies. Experiment results on NAS-Bench-101, NAS-Bench-201, DARTS search space and NNLQP show that our proposed framework can be used to predict the aforementioned latency and accuracy attributes of both cell architectures and whole deep neural networks, and achieves promising performance.
Semi-parametric Makeup Transfer via Semantic-aware Correspondence
Mar 04, 2022
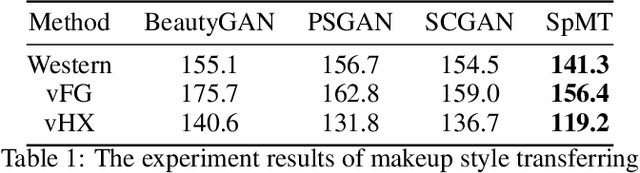
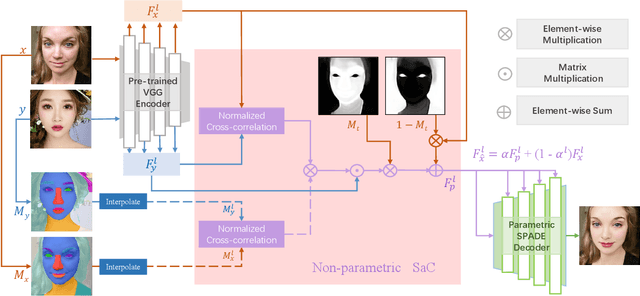
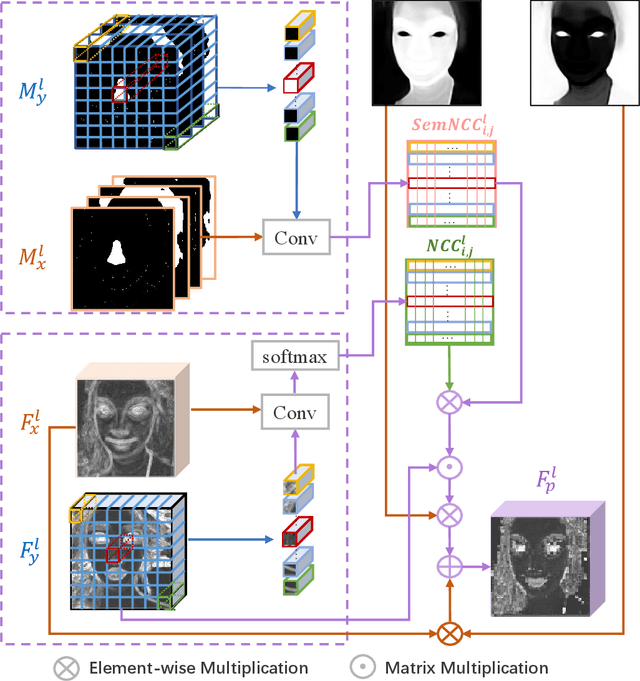
The large discrepancy between the source non-makeup image and the reference makeup image is one of the key challenges in makeup transfer. Conventional approaches for makeup transfer either learn disentangled representation or perform pixel-wise correspondence in a parametric way between two images. We argue that non-parametric techniques have a high potential for addressing the pose, expression, and occlusion discrepancies. To this end, this paper proposes a \textbf{S}emi-\textbf{p}arametric \textbf{M}akeup \textbf{T}ransfer (SpMT) method, which combines the reciprocal strengths of non-parametric and parametric mechanisms. The non-parametric component is a novel \textbf{S}emantic-\textbf{a}ware \textbf{C}orrespondence (SaC) module that explicitly reconstructs content representation with makeup representation under the strong constraint of component semantics. The reconstructed representation is desired to preserve the spatial and identity information of the source image while "wearing" the makeup of the reference image. The output image is synthesized via a parametric decoder that draws on the reconstructed representation. Extensive experiments demonstrate the superiority of our method in terms of visual quality, robustness, and flexibility. Code and pre-trained model are available at \url{https://github.com/AnonymScholar/SpMT.