 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEagleEye: Attack-Agnostic Defense against Adversarial Inputs (Technical Report)
Aug 01, 2018



Deep neural networks (DNNs) are inherently vulnerable to adversarial inputs: such maliciously crafted samples trigger DNNs to misbehave, leading to detrimental consequences for DNN-powered systems. The fundamental challenges of mitigating adversarial inputs stem from their adaptive and variable nature. Existing solutions attempt to improve DNN resilience against specific attacks; yet, such static defenses can often be circumvented by adaptively engineered inputs or by new attack variants. Here, we present EagleEye, an attack-agnostic adversarial tampering analysis engine for DNN-powered systems. Our design exploits the {\em minimality principle} underlying many attacks: to maximize the attack's evasiveness, the adversary often seeks the minimum possible distortion to convert genuine inputs to adversarial ones. We show that this practice entails the distinct distributional properties of adversarial inputs in the input space. By leveraging such properties in a principled manner, EagleEye effectively discriminates adversarial inputs and even uncovers their correct classification outputs. Through extensive empirical evaluation using a range of benchmark datasets and DNN models, we validate EagleEye's efficacy. We further investigate the adversary's possible countermeasures, which implies a difficult dilemma for her: to evade EagleEye's detection, excessive distortion is necessary, thereby significantly reducing the attack's evasiveness regarding other detection mechanisms.
Where Classification Fails, Interpretation Rises
Dec 02, 2017
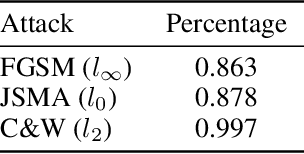
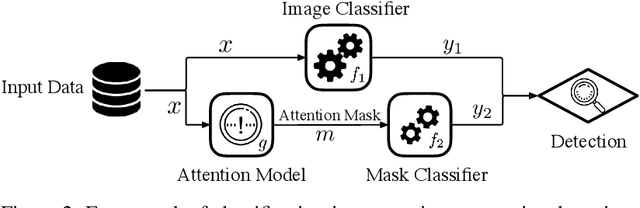

An intriguing property of deep neural networks is their inherent vulnerability to adversarial inputs, which significantly hinders their application in security-critical domains. Most existing detection methods attempt to use carefully engineered patterns to distinguish adversarial inputs from their genuine counterparts, which however can often be circumvented by adaptive adversaries. In this work, we take a completely different route by leveraging the definition of adversarial inputs: while deceiving for deep neural networks, they are barely discernible for human visions. Building upon recent advances in interpretable models, we construct a new detection framework that contrasts an input's interpretation against its classification. We validate the efficacy of this framework through extensive experiments using benchmark datasets and attacks. We believe that this work opens a new direction for designing adversarial input detection methods.
Modular Learning Component Attacks: Today's Reality, Tomorrow's Challenge
Aug 25, 2017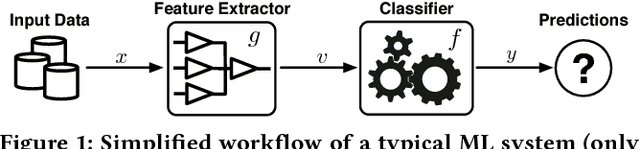


Many of today's machine learning (ML) systems are not built from scratch, but are compositions of an array of {\em modular learning components} (MLCs). The increasing use of MLCs significantly simplifies the ML system development cycles. However, as most MLCs are contributed and maintained by third parties, their lack of standardization and regulation entails profound security implications. In this paper, for the first time, we demonstrate that potentially harmful MLCs pose immense threats to the security of ML systems. We present a broad class of {\em logic-bomb} attacks in which maliciously crafted MLCs trigger host systems to malfunction in a predictable manner. By empirically studying two state-of-the-art ML systems in the healthcare domain, we explore the feasibility of such attacks. For example, we show that, without prior knowledge about the host ML system, by modifying only 3.3{\textperthousand} of the MLC's parameters, each with distortion below $10^{-3}$, the adversary is able to force the misdiagnosis of target victims' skin cancers with 100\% success rate. We provide analytical justification for the success of such attacks, which points to the fundamental characteristics of today's ML models: high dimensionality, non-linearity, and non-convexity. The issue thus seems fundamental to many ML systems. We further discuss potential countermeasures to mitigate MLC-based attacks and their potential technical challenges.