 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Learning Component Attacks: Today's Reality, Tomorrow's Challenge
Paper and Code
Aug 25, 2017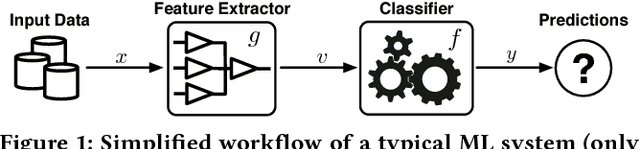


Many of today's machine learning (ML) systems are not built from scratch, but are compositions of an array of {\em modular learning components} (MLCs). The increasing use of MLCs significantly simplifies the ML system development cycles. However, as most MLCs are contributed and maintained by third parties, their lack of standardization and regulation entails profound security implications. In this paper, for the first time, we demonstrate that potentially harmful MLCs pose immense threats to the security of ML systems. We present a broad class of {\em logic-bomb} attacks in which maliciously crafted MLCs trigger host systems to malfunction in a predictable manner. By empirically studying two state-of-the-art ML systems in the healthcare domain, we explore the feasibility of such attacks. For example, we show that, without prior knowledge about the host ML system, by modifying only 3.3{\textperthousand} of the MLC's parameters, each with distortion below $10^{-3}$, the adversary is able to force the misdiagnosis of target victims' skin cancers with 100\% success rate. We provide analytical justification for the success of such attacks, which points to the fundamental characteristics of today's ML models: high dimensionality, non-linearity, and non-convexity. The issue thus seems fundamental to many ML systems. We further discuss potential countermeasures to mitigate MLC-based attacks and their potential technical challenges.