 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Classification Fails, Interpretation Rises
Paper and Code
Dec 02, 2017
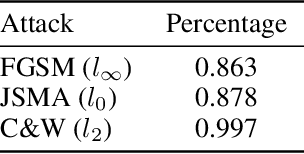
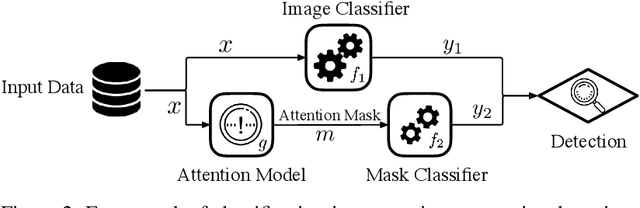

An intriguing property of deep neural networks is their inherent vulnerability to adversarial inputs, which significantly hinders their application in security-critical domains. Most existing detection methods attempt to use carefully engineered patterns to distinguish adversarial inputs from their genuine counterparts, which however can often be circumvented by adaptive adversaries. In this work, we take a completely different route by leveraging the definition of adversarial inputs: while deceiving for deep neural networks, they are barely discernible for human visions. Building upon recent advances in interpretable models, we construct a new detection framework that contrasts an input's interpretation against its classification. We validate the efficacy of this framework through extensive experiments using benchmark datasets and attacks. We believe that this work opens a new direction for designing adversarial input detection methods.