 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Provable Backdoor Defense in Collaborative Learning
Jan 19, 2021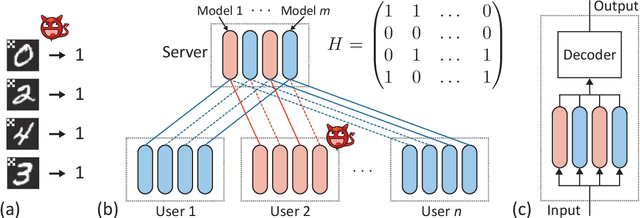
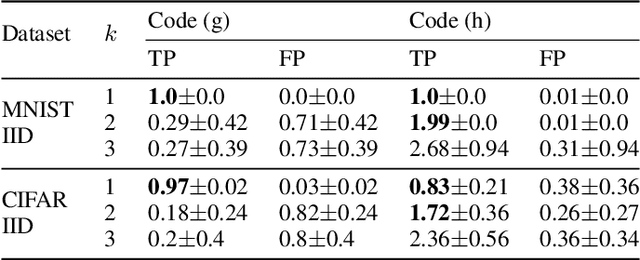


As collaborative learning allows joint training of a model using multiple sources of data, the security problem has been a central concern. Malicious users can upload poisoned data to prevent the model's convergence or inject hidden backdoors. The so-called backdoor attacks are especially difficult to detect since the model behaves normally on standard test data but gives wrong outputs when triggered by certain backdoor keys. Although Byzantine-tolerant training algorithms provide convergence guarantee, provable defense against backdoor attacks remains largely unsolved. Methods based on randomized smoothing can only correct a small number of corrupted pixels or labels; methods based on subset aggregation cause a severe drop in classification accuracy due to low data utilization. We propose a novel framework that generalizes existing subset aggregation methods. The framework shows that the subset selection process, a deciding factor for subset aggregation methods, can be viewed as a code design problem. We derive the theoretical bound of data utilization ratio and provide optimal code construction. Experiments on non-IID versions of MNIST and CIFAR-10 show that our method with optimal codes significantly outperforms baselines using non-overlapping partition and random selection. Additionally, integration with existing coding theory results shows that special codes can track the location of the attackers. Such capability provides new countermeasures to backdoor attacks.