 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScan-to-BIM for As-built Roads: Automatic Road Digital Twinning from Semantically Labeled Point Cloud Data
Jun 18, 2024



Creating geometric digital twins (gDT) for as-built roads still faces many challenges, such as low automation level and accuracy, limited asset types and shapes, and reliance on engineering experience. A novel scan-to-building information modeling (scan-to-BIM) framework is proposed for automatic road gDT creation based on semantically labeled point cloud data (PCD), which considers six asset types: Road Surface, Road Side (Slope), Road Lane (Marking), Road Sign, Road Light, and Guardrail. The framework first segments the semantic PCD into spatially independent instances or parts, then extracts the sectional polygon contours as their representative geometric information, stored in JavaScript Object Notation (JSON) files using a new data structure. Primitive gDTs are finally created from JSON files using corresponding conversion algorithms. The proposed method achieves an average distance error of 1.46 centimeters and a processing speed of 6.29 meters per second on six real-world road segments with a total length of 1,200 meters.
SDNIA-YOLO: A Robust Object Detection Model for Extreme Weather Conditions
Jun 18, 2024
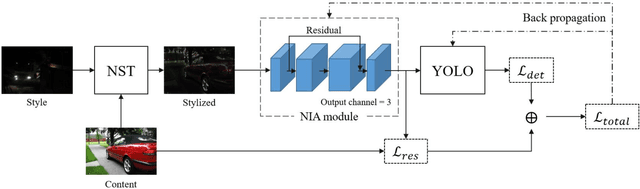
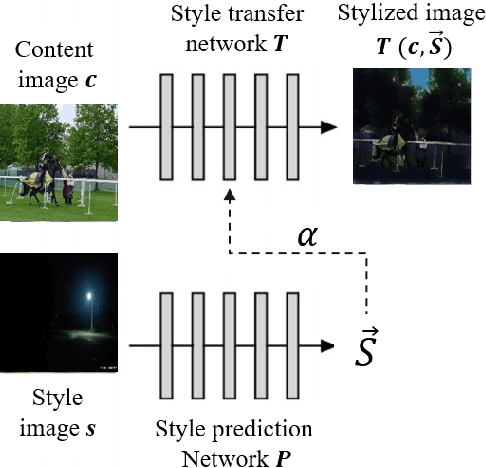

Though current object detection models based on deep learning have achieved excellent results on many conventional benchmark datasets, their performance will dramatically decline on real-world images taken under extreme conditions. Existing methods either used image augmentation based on traditional image processing algorithms or applied customized and scene-limited image adaptation technologies for robust modeling. This study thus proposes a stylization data-driven neural-image-adaptive YOLO (SDNIA-YOLO), which improves the model's robustness by enhancing image quality adaptively and learning valuable information related to extreme weather conditions from images synthesized by neural style transfer (NST). Experiments show that the developed SDNIA-YOLOv3 achieves significant mAP@.5 improvements of at least 15% on the real-world foggy (RTTS) and lowlight (ExDark) test sets compared with the baseline model. Besides, the experiments also highlight the outstanding potential of stylization data in simulating extreme weather conditions. The developed SDNIA-YOLO remains excellent characteristics of the native YOLO to a great extent, such as end-to-end one-stage, data-driven, and fast.
Personal Protective Equipment Detection in Extreme Construction Conditions
Jul 25, 2023Object detection has been widely applied for construction safety management, especially personal protective equipment (PPE) detection. Though the existing PPE detection models trained on conventional datasets have achieved excellent results, their performance dramatically declines in extreme construction conditions. A robust detection model NST-YOLOv5 is developed by combining the neural style transfer (NST) and YOLOv5 technologies. Five extreme conditions are considered and simulated via the NST module to endow the detection model with excellent robustness, including low light, intense light, sand dust, fog, and rain. Experiments show that the NST has great potential as a tool for extreme data synthesis since it is better at simulating extreme conditions than other traditional image processing algorithms and helps the NST-YOLOv5 achieve 0.141 and 0.083 mAP_(05:95) improvements in synthesized and real-world extreme data. This study provides a new feasible way to obtain a more robust detection model for extreme construction conditions.
Scene restoration from scaffold occlusion using deep learning-based methods
May 30, 2023



The occlusion issues of computer vision (CV) applications in construction have attracted significant attention, especially those caused by the wide-coverage, crisscrossed, and immovable scaffold. Intuitively, removing the scaffold and restoring the occluded visual information can provide CV agents with clearer site views and thus help them better understand the construction scenes. Therefore, this study proposes a novel two-step method combining pixel-level segmentation and image inpainting for restoring construction scenes from scaffold occlusion. A low-cost data synthesis method based only on unlabeled data is developed to address the shortage dilemma of labeled data. Experiments on the synthesized test data show that the proposed method achieves performances of 92% mean intersection over union (MIoU) for scaffold segmentation and over 82% structural similarity (SSIM) for scene restoration from scaffold occlusion.
VCVW-3D: A Virtual Construction Vehicles and Workers Dataset with 3D Annotations
May 29, 2023Currently, object detection applications in construction are almost based on pure 2D data (both image and annotation are 2D-based), resulting in the developed artificial intelligence (AI) applications only applicable to some scenarios that only require 2D information. However, most advanced applications usually require AI agents to perceive 3D spatial information, which limits the further development of the current computer vision (CV) in construction. The lack of 3D annotated datasets for construction object detection worsens the situation. Therefore, this study creates and releases a virtual dataset with 3D annotations named VCVW-3D, which covers 15 construction scenes and involves ten categories of construction vehicles and workers. The VCVW-3D dataset is characterized by multi-scene, multi-category, multi-randomness, multi-viewpoint, multi-annotation, and binocular vision. Several typical 2D and monocular 3D object detection models are then trained and evaluated on the VCVW-3D dataset to provide a benchmark for subsequent research. The VCVW-3D is expected to bring considerable economic benefits and practical significance by reducing the costs of data construction, prototype development, and exploration of space-awareness applications, thus promoting the development of CV in construction, especially those of 3D applications.
Monocular 2D Camera-based Proximity Monitoring for Human-Machine Collision Warning on Construction Sites
May 29, 2023Accident of struck-by machines is one of the leading causes of casualties on construction sites. Monitoring workers' proximities to avoid human-machine collisions has aroused great concern in construction safety management. Existing methods are either too laborious and costly to apply extensively, or lacking spatial perception for accurate monitoring. Therefore, this study proposes a novel framework for proximity monitoring using only an ordinary 2D camera to realize real-time human-machine collision warning, which is designed to integrate a monocular 3D object detection model to perceive spatial information from 2D images and a post-processing classification module to identify the proximity as four predefined categories: Dangerous, Potentially Dangerous, Concerned, and Safe. A virtual dataset containing 22000 images with 3D annotations is constructed and publicly released to facilitate the system development and evaluation. Experimental results show that the trained 3D object detection model achieves 75% loose AP within 20 meters. Besides, the implemented system is real-time and camera carrier-independent, achieving an F1 of roughly 0.8 within 50 meters under specified settings for machines of different sizes. This study preliminarily reveals the potential and feasibility of proximity monitoring using only a 2D camera, providing a new promising and economical way for early warning of human-machine collisions.