 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Privacy-Preserving Outsourced Convolutional Neural Network Predictions
Mar 09, 2020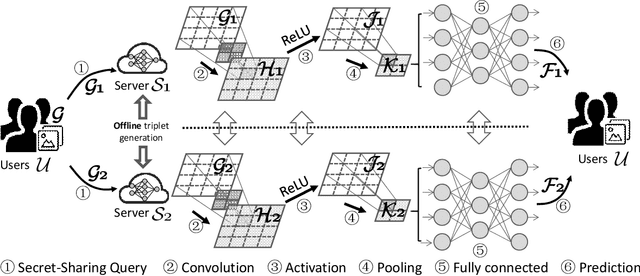
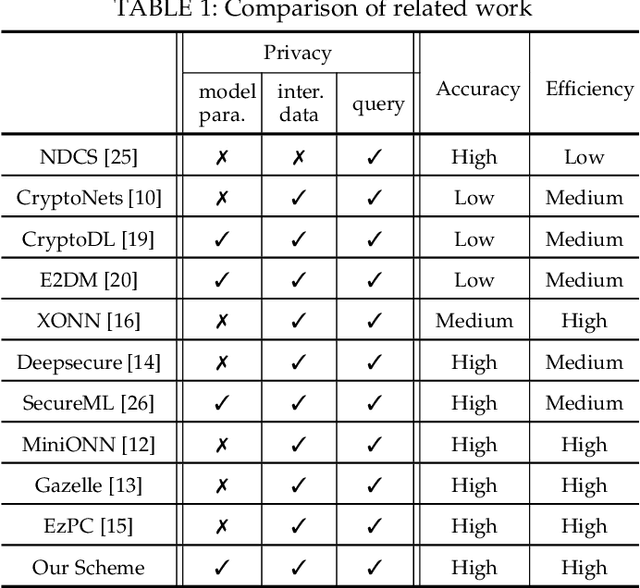
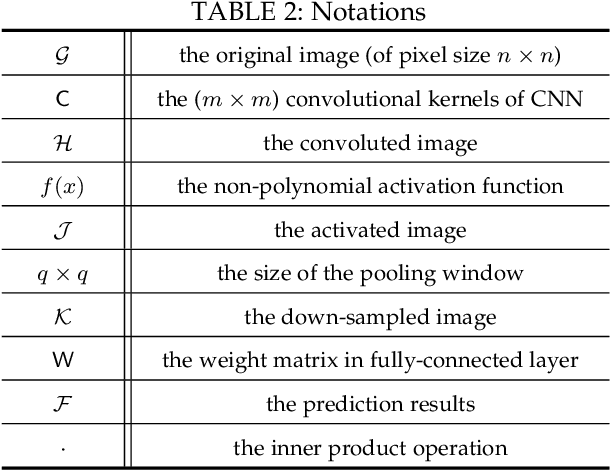

Neural networks provide better prediction performance than previous techniques. Prediction-as-a-service thus becomes popular, especially in the outsourced setting since it involves extensive computation. Recent researches focus on the privacy of the query and results, but they do not provide model privacy against the model-hosting server and may leak partial information about the results. Some of them further require frequent interactions with the querier or heavy computation overheads. This paper proposes a new scheme for privacy-preserving neural network prediction in the outsourced setting, i.e., the server cannot learn the query, (intermediate) results, and the model. Similar to SecureML (S&P'17), a representative work which provides model privacy, we leverage two non-colluding servers with secret sharing and triplet generation to minimize the usage of heavyweight cryptography. Further, we adopt asynchronous computation to improve the throughput, and design garbled circuits for the non-polynomial activation function to keep the same accuracy as the underlying network (instead of approximating it). Our experiments on four neural network architectures show that our scheme achieves an average of 282 improvements in reducing latency compared to SecureML. Compared to MiniONN (CCS'17) and EzPC (EuroS&P'19), both without model privacy, our scheme achieves a lower latency by a factor of 18 and 10, respectively. For the communication costs, our scheme outperforms SecureML by 122, MiniONN by 49, and EzPC by 38 times.