 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Policy Learning with World-Action Model
Mar 30, 2026This paper presents the World-Action Model (WAM), an action-regularized world model that jointly reasons over future visual observations and the actions that drive state transitions. Unlike conventional world models trained solely via image prediction, WAM incorporates an inverse dynamics objective into DreamerV2 that predicts actions from latent state transitions, encouraging the learned representations to capture action-relevant structure critical for downstream control. We evaluate WAM on enhancing policy learning across eight manipulation tasks from the CALVIN benchmark. We first pretrain a diffusion policy via behavioral cloning on world model latents, then refine it with model-based PPO inside the frozen world model. Without modifying the policy architecture or training procedure, WAM improves average behavioral cloning success from 59.4% to 71.2% over DreamerV2 and DiWA baselines. After PPO fine-tuning, WAM achieves 92.8% average success versus 79.8% for the baseline, with two tasks reaching 100%, using 8.7x fewer training steps.
BetterScene: 3D Scene Synthesis with Representation-Aligned Generative Model
Feb 26, 2026We present BetterScene, an approach to enhance novel view synthesis (NVS) quality for diverse real-world scenes using extremely sparse, unconstrained photos. BetterScene leverages the production-ready Stable Video Diffusion (SVD) model pretrained on billions of frames as a strong backbone, aiming to mitigate artifacts and recover view-consistent details at inference time. Conventional methods have developed similar diffusion-based solutions to address these challenges of novel view synthesis. Despite significant improvements, these methods typically rely on off-the-shelf pretrained diffusion priors and fine-tune only the UNet module while keeping other components frozen, which still leads to inconsistent details and artifacts even when incorporating geometry-aware regularizations like depth or semantic conditions. To address this, we investigate the latent space of the diffusion model and introduce two components: (1) temporal equivariance regularization and (2) vision foundation model-aligned representation, both applied to the variational autoencoder (VAE) module within the SVD pipeline. BetterScene integrates a feed-forward 3D Gaussian Splatting (3DGS) model to render features as inputs for the SVD enhancer and generate continuous, artifact-free, consistent novel views. We evaluate on the challenging DL3DV-10K dataset and demonstrate superior performance compared to state-of-the-art methods.
UAS Visual Navigation in Large and Unseen Environments via a Meta Agent
Mar 20, 2025The aim of this work is to develop an approach that enables Unmanned Aerial System (UAS) to efficiently learn to navigate in large-scale urban environments and transfer their acquired expertise to novel environments. To achieve this, we propose a meta-curriculum training scheme. First, meta-training allows the agent to learn a master policy to generalize across tasks. The resulting model is then fine-tuned on the downstream tasks. We organize the training curriculum in a hierarchical manner such that the agent is guided from coarse to fine towards the target task. In addition, we introduce Incremental Self-Adaptive Reinforcement learning (ISAR), an algorithm that combines the ideas of incremental learning and meta-reinforcement learning (MRL). In contrast to traditional reinforcement learning (RL), which focuses on acquiring a policy for a specific task, MRL aims to learn a policy with fast transfer ability to novel tasks. However, the MRL training process is time consuming, whereas our proposed ISAR algorithm achieves faster convergence than the conventional MRL algorithm. We evaluate the proposed methodologies in simulated environments and demonstrate that using this training philosophy in conjunction with the ISAR algorithm significantly improves the convergence speed for navigation in large-scale cities and the adaptation proficiency in novel environments.
UAS Navigation in the Real World Using Visual Observation
Aug 25, 2022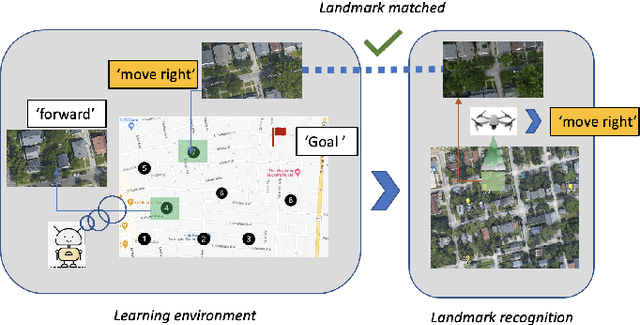
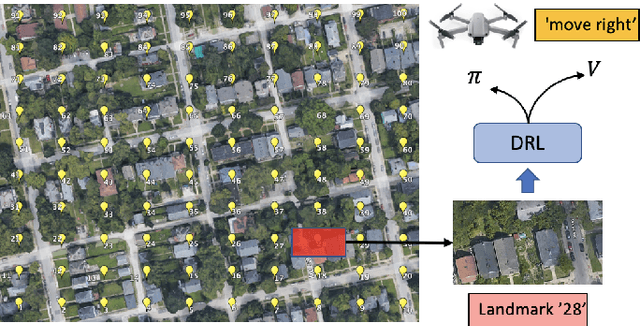

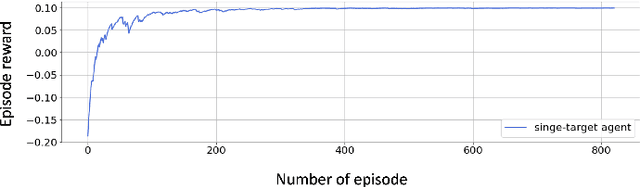
This paper presents a novel end-to-end Unmanned Aerial System (UAS) navigation approach for long-range visual navigation in the real world. Inspired by dual-process visual navigation system of human's instinct: environment understanding and landmark recognition, we formulate the UAS navigation task into two same phases. Our system combines the reinforcement learning (RL) and image matching approaches. First, the agent learns the navigation policy using RL in the specified environment. To achieve this, we design an interactive UASNAV environment for the training process. Once the agent learns the navigation policy, which means 'familiarized themselves with the environment', we let the UAS fly in the real world to recognize the landmarks using image matching method and take action according to the learned policy. During the navigation process, the UAS is embedded with single camera as the only visual sensor. We demonstrate that the UAS can learn navigating to the destination hundreds meters away from the starting point with the shortest path in the real world scenario.
Learning to Drive Using Sparse Imitation Reinforcement Learning
May 24, 2022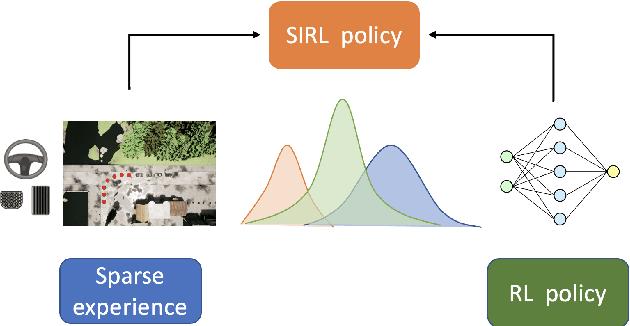

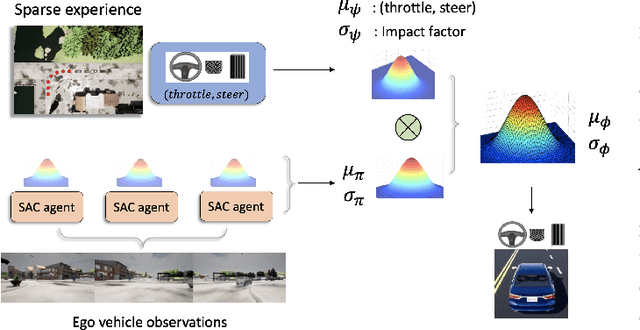
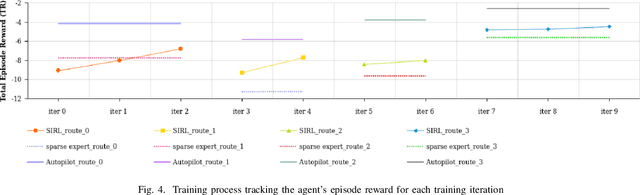
In this paper, we propose Sparse Imitation Reinforcement Learning (SIRL), a hybrid end-to-end control policy that combines the sparse expert driving knowledge with reinforcement learning (RL) policy for autonomous driving (AD) task in CARLA simulation environment. The sparse expert is designed based on hand-crafted rules which is suboptimal but provides a risk-averse strategy by enforcing experience for critical scenarios such as pedestrian and vehicle avoidance, and traffic light detection. As it has been demonstrated, training a RL agent from scratch is data-inefficient and time consuming particularly for the urban driving task, due to the complexity of situations stemming from the vast size of state space. Our SIRL strategy provides a solution to solve these problems by fusing the output distribution of the sparse expert policy and the RL policy to generate a composite driving policy. With the guidance of the sparse expert during the early training stage, SIRL strategy accelerates the training process and keeps the RL exploration from causing a catastrophe outcome, and ensures safe exploration. To some extent, the SIRL agent is imitating the driving expert's behavior. At the same time, it continuously gains knowledge during training therefore it keeps making improvement beyond the sparse expert, and can surpass both the sparse expert and a traditional RL agent. We experimentally validate the efficacy of proposed SIRL approach in a complex urban scenario within the CARLA simulator. Besides, we compare the SIRL agent's performance for risk-averse exploration and high learning efficiency with the traditional RL approach. We additionally demonstrate the SIRL agent's generalization ability to transfer the driving skill to unseen environment.