 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Drive Using Sparse Imitation Reinforcement Learning
Paper and Code
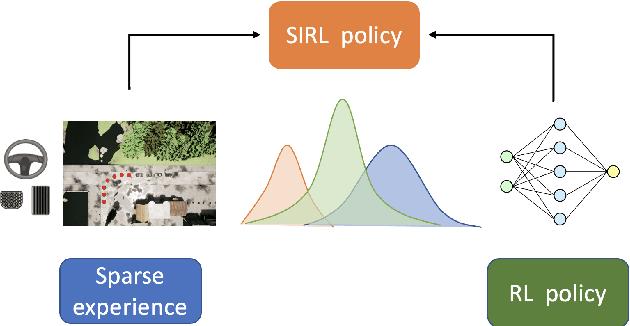

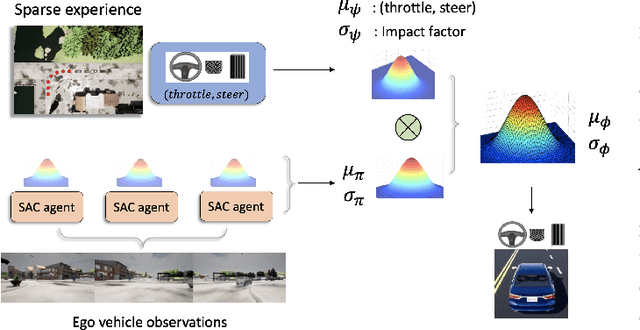
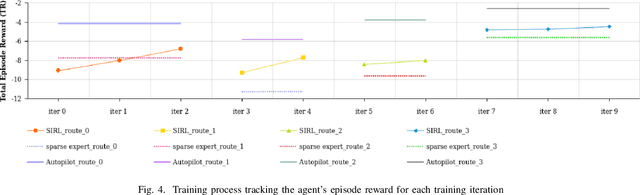
In this paper, we propose Sparse Imitation Reinforcement Learning (SIRL), a hybrid end-to-end control policy that combines the sparse expert driving knowledge with reinforcement learning (RL) policy for autonomous driving (AD) task in CARLA simulation environment. The sparse expert is designed based on hand-crafted rules which is suboptimal but provides a risk-averse strategy by enforcing experience for critical scenarios such as pedestrian and vehicle avoidance, and traffic light detection. As it has been demonstrated, training a RL agent from scratch is data-inefficient and time consuming particularly for the urban driving task, due to the complexity of situations stemming from the vast size of state space. Our SIRL strategy provides a solution to solve these problems by fusing the output distribution of the sparse expert policy and the RL policy to generate a composite driving policy. With the guidance of the sparse expert during the early training stage, SIRL strategy accelerates the training process and keeps the RL exploration from causing a catastrophe outcome, and ensures safe exploration. To some extent, the SIRL agent is imitating the driving expert's behavior. At the same time, it continuously gains knowledge during training therefore it keeps making improvement beyond the sparse expert, and can surpass both the sparse expert and a traditional RL agent. We experimentally validate the efficacy of proposed SIRL approach in a complex urban scenario within the CARLA simulator. Besides, we compare the SIRL agent's performance for risk-averse exploration and high learning efficiency with the traditional RL approach. We additionally demonstrate the SIRL agent's generalization ability to transfer the driving skill to unseen environment.