 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAMO-NLP at NLPCC-2022 Task 2: Knowledge Enhanced Robust NER for Speech Entity Linking
Sep 29, 2022Speech Entity Linking aims to recognize and disambiguate named entities in spoken languages. Conventional methods suffer gravely from the unfettered speech styles and the noisy transcripts generated by ASR systems. In this paper, we propose a novel approach called Knowledge Enhanced Named Entity Recognition (KENER), which focuses on improving robustness through painlessly incorporating proper knowledge in the entity recognition stage and thus improving the overall performance of entity linking. KENER first retrieves candidate entities for a sentence without mentions, and then utilizes the entity descriptions as extra information to help recognize mentions. The candidate entities retrieved by a dense retrieval module are especially useful when the input is short or noisy. Moreover, we investigate various data sampling strategies and design effective loss functions, in order to improve the quality of retrieved entities in both recognition and disambiguation stages. Lastly, a linking with filtering module is applied as the final safeguard, making it possible to filter out wrongly-recognized mentions. Our system achieves 1st place in Track 1 and 2nd place in Track 2 of NLPCC-2022 Shared Task 2.
Similar Scenes arouse Similar Emotions: Parallel Data Augmentation for Stylized Image Captioning
Aug 26, 2021

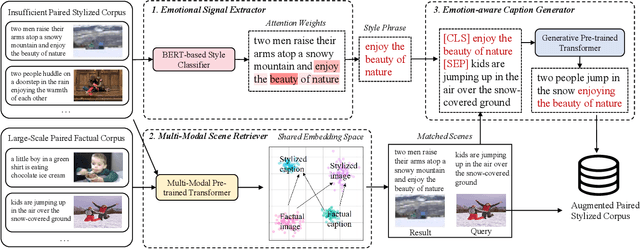
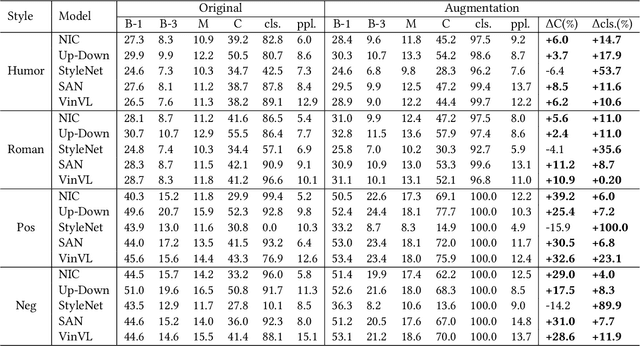
Stylized image captioning systems aim to generate a caption not only semantically related to a given image but also consistent with a given style description. One of the biggest challenges with this task is the lack of sufficient paired stylized data. Many studies focus on unsupervised approaches, without considering from the perspective of data augmentation. We begin with the observation that people may recall similar emotions when they are in similar scenes, and often express similar emotions with similar style phrases, which underpins our data augmentation idea. In this paper, we propose a novel Extract-Retrieve-Generate data augmentation framework to extract style phrases from small-scale stylized sentences and graft them to large-scale factual captions. First, we design the emotional signal extractor to extract style phrases from small-scale stylized sentences. Second, we construct the plugable multi-modal scene retriever to retrieve scenes represented with pairs of an image and its stylized caption, which are similar to the query image or caption in the large-scale factual data. In the end, based on the style phrases of similar scenes and the factual description of the current scene, we build the emotion-aware caption generator to generate fluent and diversified stylized captions for the current scene. Extensive experimental results show that our framework can alleviate the data scarcity problem effectively. It also significantly boosts the performance of several existing image captioning models in both supervised and unsupervised settings, which outperforms the state-of-the-art stylized image captioning methods in terms of both sentence relevance and stylishness by a substantial margin.