 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAPA-based Dynamic Privacy Optimization for Wireless Federated Learning in Heterogeneous Environments
May 26, 2025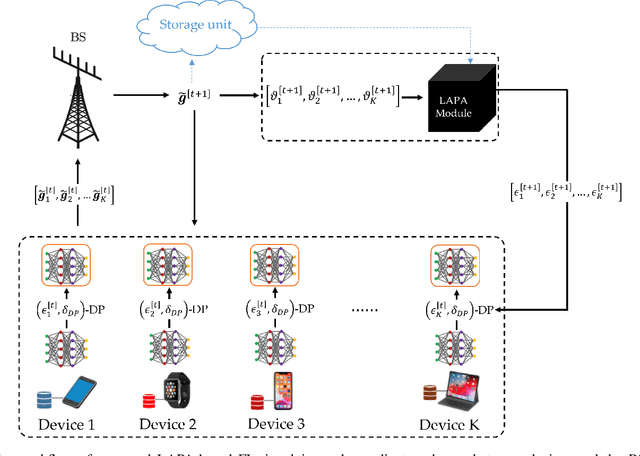

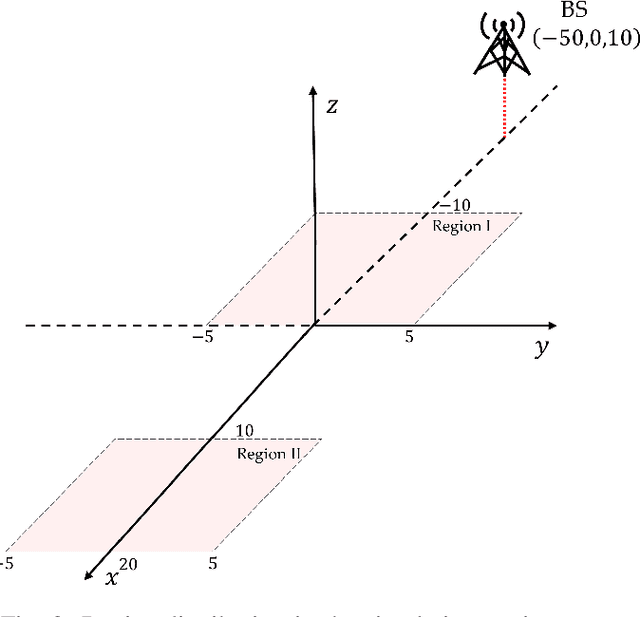
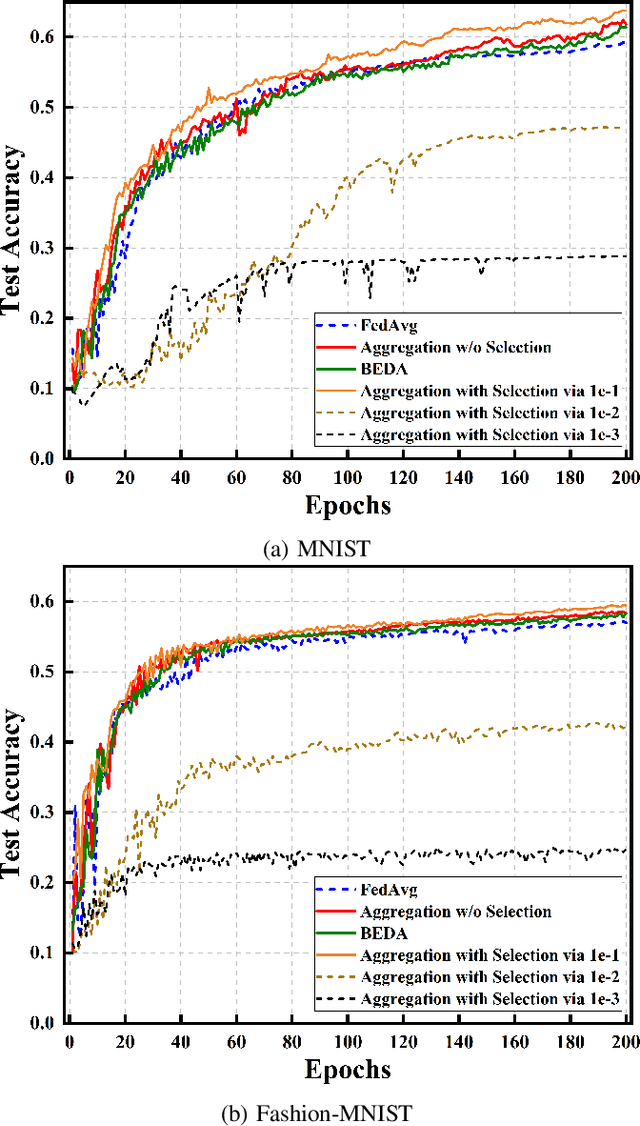
Federated Learning (FL) is a distributed machine learning paradigm based on protecting data privacy of devices, which however, can still be broken by gradient leakage attack via parameter inversion techniques. Differential privacy (DP) technology reduces the risk of private data leakage by adding artificial noise to the gradients, but detrimental to the FL utility at the same time, especially in the scenario where the data is Non-Independent Identically Distributed (Non-IID). Based on the impact of heterogeneous data on aggregation performance, this paper proposes a Lightweight Adaptive Privacy Allocation (LAPA) strategy, which assigns personalized privacy budgets to devices in each aggregation round without transmitting any additional information beyond gradients, ensuring both privacy protection and aggregation efficiency. Furthermore, the Deep Deterministic Policy Gradient (DDPG) algorithm is employed to optimize the transmission power, in order to determine the optimal timing at which the adaptively attenuated artificial noise aligns with the communication noise, enabling an effective balance between DP and system utility. Finally, a reliable aggregation strategy is designed by integrating communication quality and data distribution characteristics, which improves aggregation performance while preserving privacy. Experimental results demonstrate that the personalized noise allocation and dynamic optimization strategy based on LAPA proposed in this paper enhances convergence performance while satisfying the privacy requirements of FL.
Dynamic Relay Selection and Power Allocation for Minimizing Outage Probability: A Hierarchical Reinforcement Learning Approach
Nov 10, 2020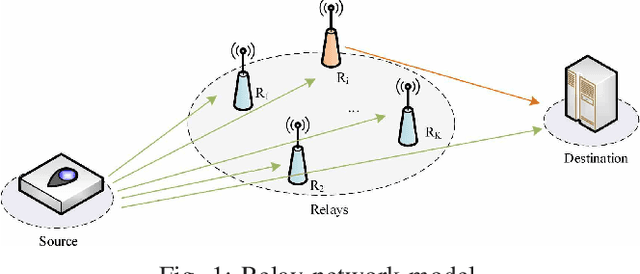
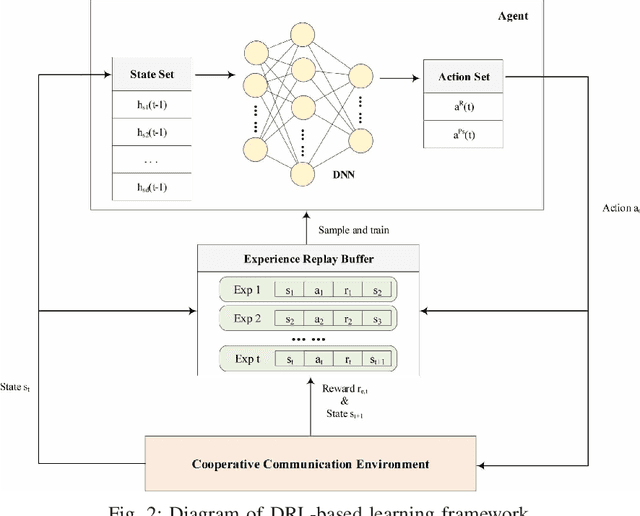
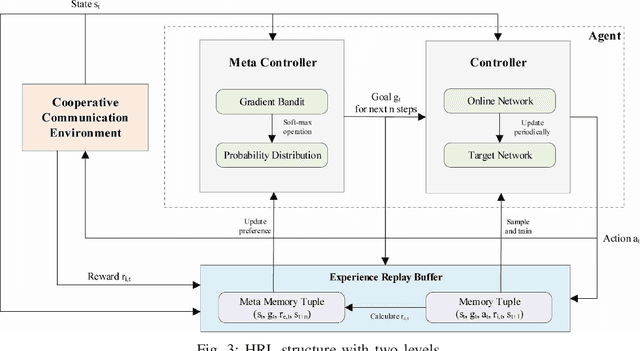
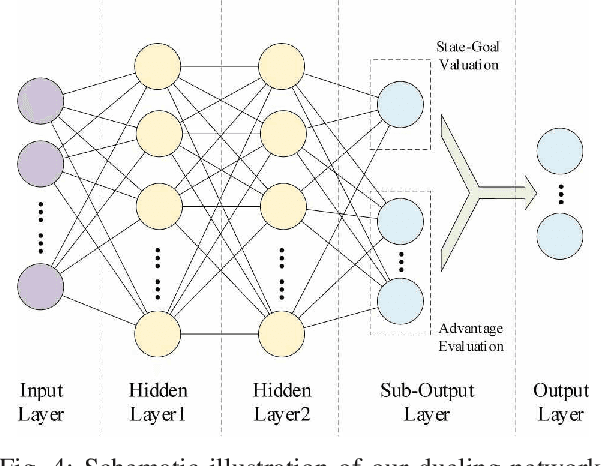
Cooperative communication is an effective approach to improve spectrum utilization. When considering relay selection and power allocation in cooperative communication, most of the existing studies require the assumption of channel state information (CSI). However, it is difficult to get an accurate CSI in practice. In this paper, we consider an outage-based method subjected to a total transmission power constraint in the two-hop cooperative communication scenario. We use reinforcement learning (RL) methods to learn strategies, and complete the optimal relay selection and power allocation, which do not need any prior knowledge of CSI but simply rely on the interaction with the communication environment. It is noted that conventional RL methods, including common deep reinforcement learning (DRL) methods, perform poorly when the search space is large. Therefore, we first propose a practical DRL framework with an outage-based reward function, which is used as a baseline. Then, we further propose our novel hierarchical reinforcement learning (HRL) algorithm for dynamic relay selection and power allocation. A key difference from other RL-based methods in existing literatures is that, our HRL approach decomposes relay selection and power allocation into two hierarchical optimization objectives, which are trained in different levels. Simulation results reveal that our HRL algorithm trains faster and obtains a lower outage probability when compared with traditional DRL methods, especially in a sparse reward environment.
Deep Reinforcement Learning Based Dynamic Route Planning for Minimizing Travel Time
Nov 03, 2020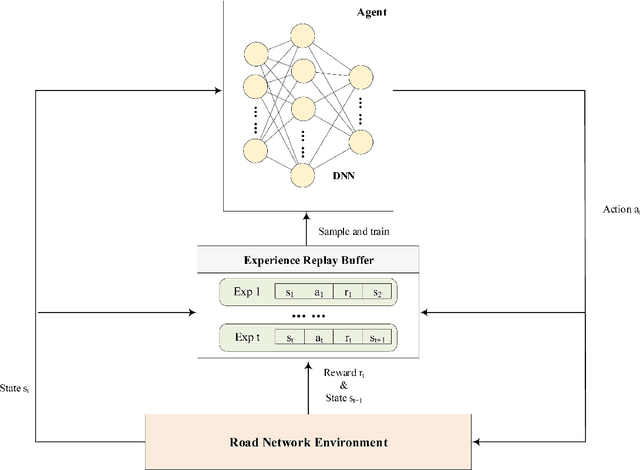
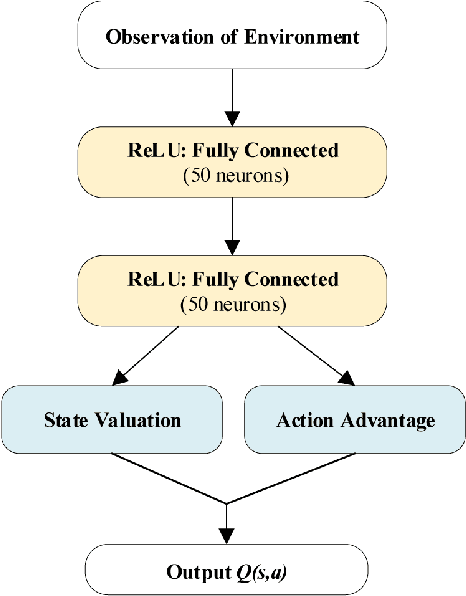

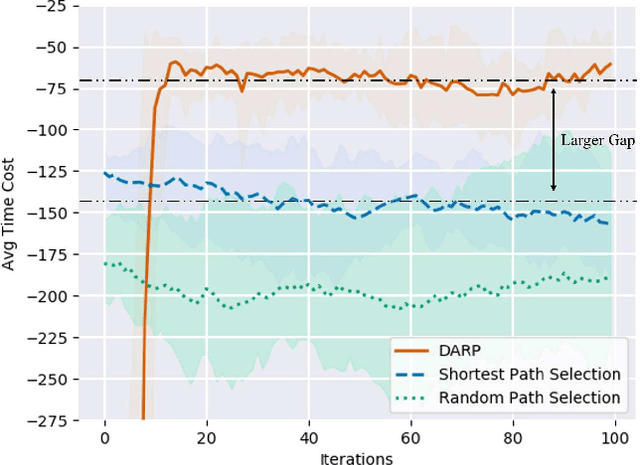
Route planning is important in transportation. Existing works focus on finding the shortest path solution or using metrics such as safety and energy consumption to determine the planning. It is noted that most of these studies rely on prior knowledge of road network, which may be not available in certain situations. In this paper, we design a route planning algorithm based on deep reinforcement learning (DRL) for pedestrians. We use travel time consumption as the metric, and plan the route by predicting pedestrian flow in the road network. We put an agent, which is an intelligent robot, on a virtual map. Different from previous studies, our approach assumes that the agent does not need any prior information about road network, but simply relies on the interaction with the environment. We propose a dynamically adjustable route planning (DARP) algorithm, where the agent learns strategies through a dueling deep Q network to avoid congested roads. Simulation results show that the DARP algorithm saves 52% of the time under congestion condition when compared with traditional shortest path planning algorithms.