 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-aware Plug-and-play Scheme for Semantic Segmentation
Mar 18, 2023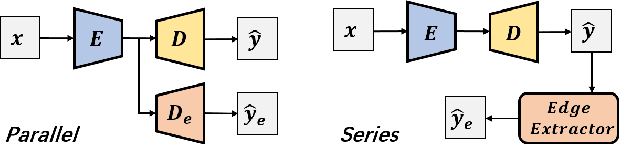
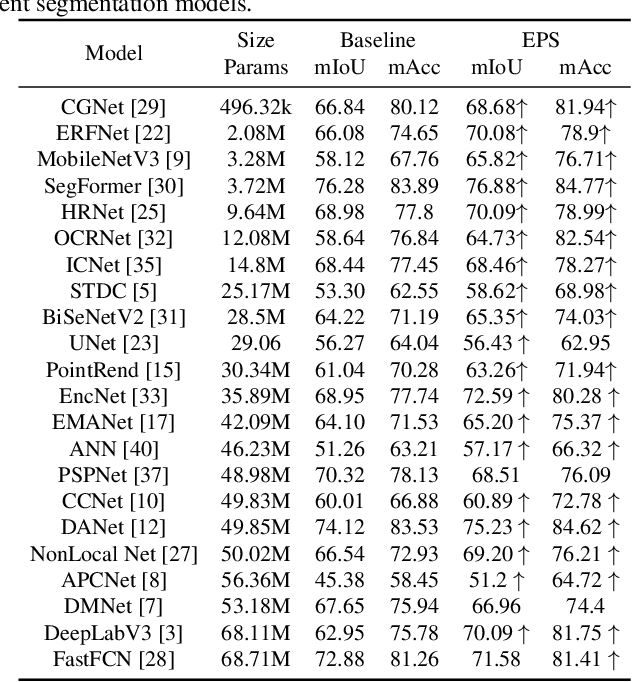
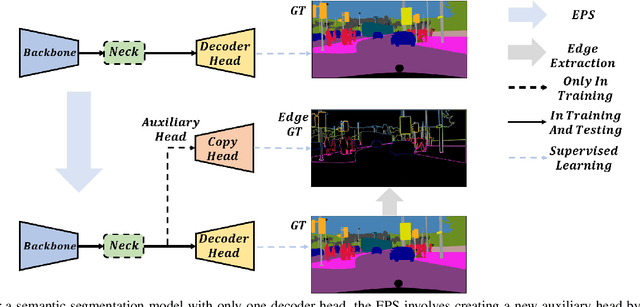
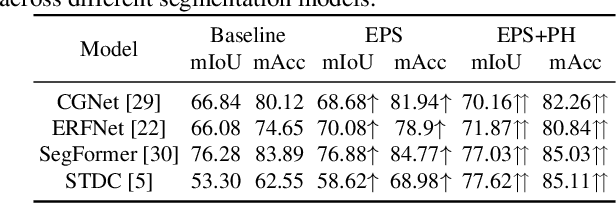
Semantic segmentation is a classic and fundamental computer vision problem dedicated to assigning each pixel with its corresponding class. Some recent methods introduce edge-based information for improving the segmentation performance. However these methods are specific and limited to certain network architectures, and they can not be transferred to other models or tasks. Therefore, we propose an abstract and universal edge supervision method called Edge-aware Plug-and-play Scheme (EPS), which can be easily and quickly applied to any semantic segmentation models. The core is edge-width/thickness preserving guided for semantic segmentation. The EPS first extracts the Edge Ground Truth (Edge GT) with a predefined edge thickness from the training data; and then for any network architecture, it directly copies the decoder head for the auxiliary task with the Edge GT supervision. To ensure the edge thickness preserving consistantly, we design a new boundarybased loss, called Polar Hausdorff (PH) Loss, for the auxiliary supervision. We verify the effectiveness of our EPS on the Cityscapes dataset using 22 models. The experimental results indicate that the proposed method can be seamlessly integrated into any state-of-the-art (SOTA) models with zero modification, resulting in promising enhancement of the segmentation performance.
Mask Focal Loss: A unifying framework for dense crowd counting with canonical object detection networks
Jan 04, 2023



As a fundamental computer vision task, crowd counting predicts the number of pedestrians in a scene, which plays an important role in risk perception and early warning, traffic control and scene statistical analysis. Currently, deep learning based head detection is a promising method for crowd counting. However, the highly concerned object detection networks cannot be well applied to this field for three reasons: (1) The sample imbalance has not been overcome yet in highly dense and complex scenes because the existing loss functions calculate the positive loss at a single key point or in the entire target area with the same weight for all pixels; (2) The canonical object detectors' loss calculation is a hard assignment without taking into account the space coherence from the object location to the background region; and (3) Most of the existing head detection datasets are only annotated with the center points instead of bounding boxes which is mandatory for the canonical detectors. To address these problems, we propose a novel loss function, called Mask Focal Loss (MFL), to redefine the loss contributions according to the situ value of the heatmap with a Gaussian kernel. MFL provides a unifying framework for the loss functions based on both heatmap and binary feature map ground truths. Meanwhile, for better evaluation and comparison, a new synthetic dataset GTA\_Head is built, including 35 sequences, 5096 images and 1732043 head labels with bounding boxes. Experimental results show the overwhelming performance and demonstrate that our proposed MFL framework is applicable to all of the canonical detectors and to various datasets with different annotation patterns. This work provides a strong baseline for surpassing the crowd counting methods based on density estimation.
Harmonizing Output Imbalance for semantic segmentation on extremely-imbalanced input data
Nov 10, 2022



Semantic segmentation is a high level computer vision task that assigns a label for each pixel of an image. It is challengeful to deal with extremely-imbalanced data in which the ratio of target ixels to background pixels is lower than 1:1000. Such severe input imbalance leads to output imbalance for poor model training. This paper considers three issues for extremely-imbalanced data: inspired by the region based loss, an implicit measure for the output imbalance is proposed, and an adaptive algorithm is designed for guiding the output imbalance hyperparameter selection; then it is generalized to distribution based loss for dealing with output imbalance; and finally a compound loss with our adaptive hyperparameter selection alogorithm can keep the consistency of training and inference for harmonizing the output imbalance. With four popular deep architectures on our private dataset with three input imbalance scales and three public datasets, extensive experiments demonstrate the ompetitive/promising performance of the proposed method.