 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaigiSpeech: A Low-Resource Real-World Speech Intent Dataset and Preliminary Results with Scalable Data Mining In-the-Wild
Mar 23, 2026Speech technologies have advanced rapidly and serve diverse populations worldwide. However, many languages remain underrepresented due to limited resources. In this paper, we introduce \textbf{TaigiSpeech}, a real-world speech intent dataset in Taiwanese Taigi (aka Taiwanese Hokkien/Southern Min), which is a low-resource and primarily spoken language. The dataset is collected from older adults, comprising 21 speakers with a total of 3k utterances. It is designed for practical intent detection scenarios, including healthcare and home assistant applications. To address the scarcity of labeled data, we explore two data mining strategies with two levels of supervision: keyword match data mining with LLM pseudo labeling via an intermediate language and an audio-visual framework that leverages multimodal cues with minimal textual supervision. This design enables scalable dataset construction for low-resource and unwritten spoken languages. TaigiSpeech will be released under the CC BY 4.0 license to facilitate broad adoption and research on low-resource and unwritten languages. The project website and the dataset can be found on https://kwchang.org/taigispeech.
How Auditory Knowledge in LLM Backbones Shapes Audio Language Models: A Holistic Evaluation
Mar 19, 2026Large language models (LLMs) have been widely used as knowledge backbones of Large Audio Language Models (LALMs), yet how much auditory knowledge they encode through text-only pre-training and how this affects downstream performance remains unclear. We study this gap by comparing different LLMs under two text-only and one audio-grounded setting: (1) direct probing on AKB-2000, a curated benchmark testing the breadth and depth of auditory knowledge; (2) cascade evaluation, where LLMs reason over text descriptions from an audio captioner; and (3) audio-grounded evaluation, where each LLM is fine-tuned into a Large Audio Language Model (LALM) with an audio encoder. Our findings reveal that auditory knowledge varies substantially across families, and text-only results are strongly correlated with audio performance. Our work provides empirical grounding for a comprehensive understanding of LLMs in audio research.
Nudging Hidden States: Training-Free Model Steering for Chain-of-Thought Reasoning in Large Audio-Language Models
Mar 15, 2026Chain-of-thought (CoT) prompting has been extended to large audio-language models (LALMs) to elicit reasoning, yet enhancing its effectiveness without training remains challenging. We study inference-time model steering as a training-free approach to improve LALM reasoning. We introduce three strategies using diverse information sources and evaluate them across four LALMs and four benchmarks. Results show general accuracy gains up to 4.4% over CoT prompting. Notably, we identify a cross-modal transfer where steering vectors derived from few text samples effectively guide speech-based reasoning, demonstrating high data efficiency. We also examine hyperparameter sensitivity to understand the robustness of these approaches. Our findings position model steering as a practical direction for strengthening LALM reasoning.
Finite-Horizon Quickest Change Detection Balancing Latency with False Alarm Probability
Nov 16, 2025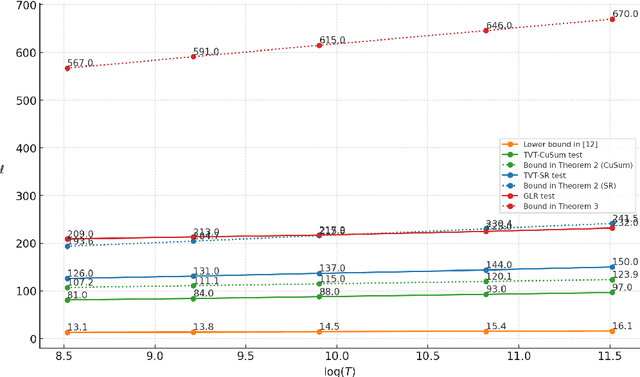
A finite-horizon variant of the quickest change detection (QCD) problem that is of relevance to learning in non-stationary environments is studied. The metric characterizing false alarms is the probability of a false alarm occurring before the horizon ends. The metric that characterizes the delay is \emph{latency}, which is the smallest value such that the probability that detection delay exceeds this value is upper bounded to a predetermined latency level. The objective is to minimize the latency (at a given latency level), while maintaining a low false alarm probability. Under the pre-specified latency and false alarm levels, a universal lower bound on the latency, which any change detection procedure needs to satisfy, is derived. Change detectors are then developed, which are order-optimal in terms of the horizon. The case where the pre- and post-change distributions are known is considered first, and then the results are generalized to the non-parametric case when they are unknown except that they are sub-Gaussian with different means. Simulations are provided to validate the theoretical results.
Detection Is All You Need: A Feasible Optimal Prior-Free Black-Box Approach For Piecewise Stationary Bandits
Jan 31, 2025



We study the problem of piecewise stationary bandits without prior knowledge of the underlying non-stationarity. We propose the first $\textit{feasible}$ black-box algorithm applicable to most common parametric bandit variants. Our procedure, termed Detection Augmented Bandit (DAB), is modular, accepting any stationary bandit algorithm as input and augmenting it with a change detector. DAB achieves optimal regret in the piecewise stationary setting under mild assumptions. Specifically, we prove that DAB attains the order-optimal regret bound of $\tilde{\mathcal{O}}(\sqrt{N_T T})$, where $N_T$ denotes the number of changes over the horizon $T$, if its input stationary bandit algorithm has order-optimal stationary regret guarantees. Applying DAB to different parametric bandit settings, we recover recent state-of-the-art results. Notably, for self-concordant bandits, DAB achieves optimal dynamic regret, while previous works obtain suboptimal bounds and require knowledge on the non-stationarity. In simulations on piecewise stationary environments, DAB outperforms existing approaches across varying number of changes. Interestingly, despite being theoretically designed for piecewise stationary environments, DAB is also effective in simulations in drifting environments, outperforming existing methods designed specifically for this scenario.
Change Detection-Based Procedures for Piecewise Stationary MABs: A Modular Approach
Jan 02, 2025
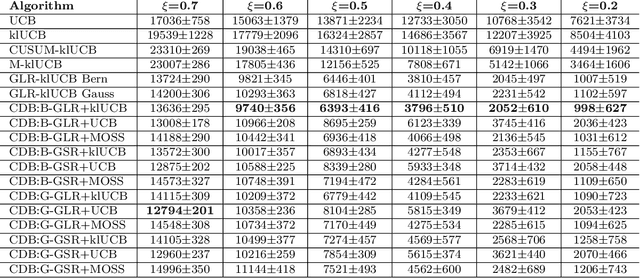
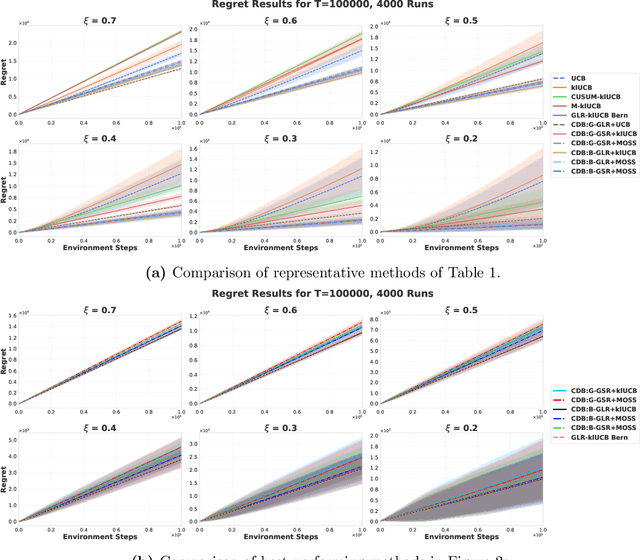
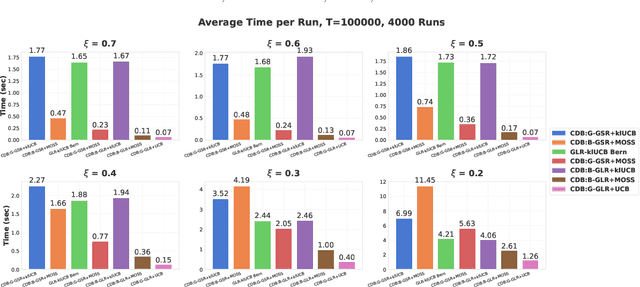
Conventional Multi-Armed Bandit (MAB) algorithms are designed for stationary environments, where the reward distributions associated with the arms do not change with time. In many applications, however, the environment is more accurately modeled as being nonstationary. In this work, piecewise stationary MAB (PS-MAB) environments are investigated, in which the reward distributions associated with a subset of the arms change at some change-points and remain stationary between change-points. Our focus is on the asymptotic analysis of PS-MABs, for which practical algorithms based on change detection (CD) have been previously proposed. Our goal is to modularize the design and analysis of such CD-based Bandit (CDB) procedures. To this end, we identify the requirements for stationary bandit algorithms and change detectors in a CDB procedure that are needed for the modularization. We assume that the rewards are sub-Gaussian. Under this assumption and a condition on the separation of the change-points, we show that the analysis of CDB procedures can indeed be modularized, so that regret bounds can be obtained in a unified manner for various combinations of change detectors and bandit algorithms. Through this analysis, we develop new modular CDB procedures that are order-optimal. We compare the performance of our modular CDB procedures with various other methods in simulations.
Is Prior-Free Black-Box Non-Stationary Reinforcement Learning Feasible?
Oct 17, 2024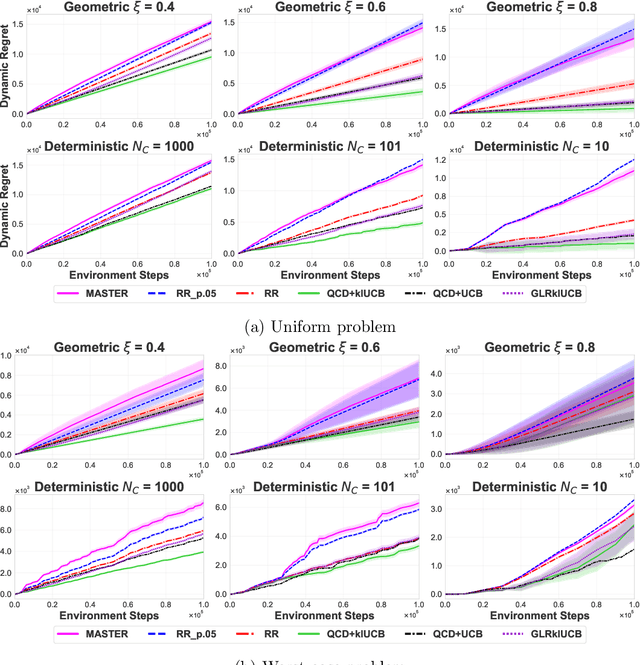
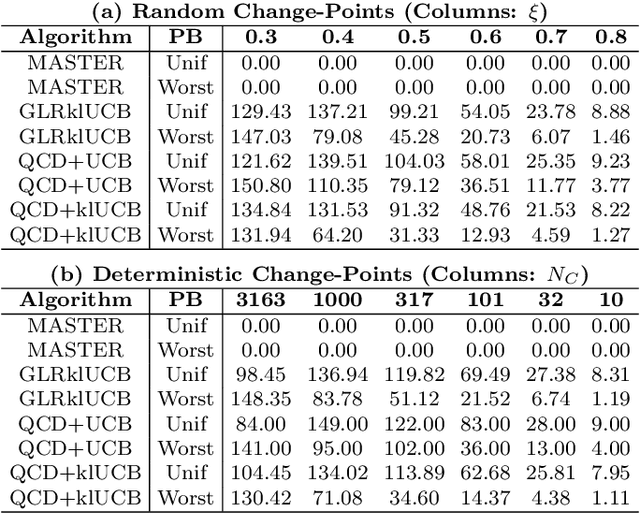
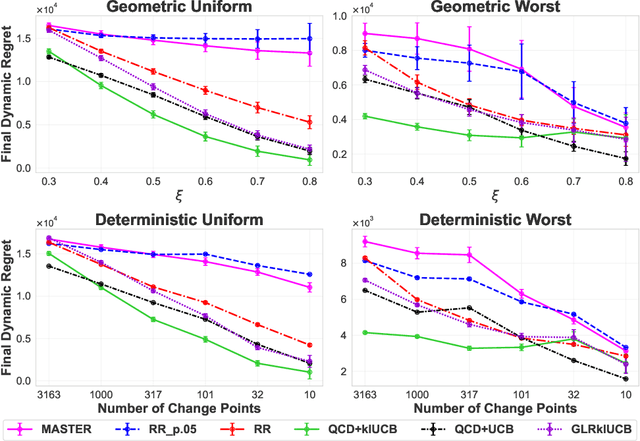
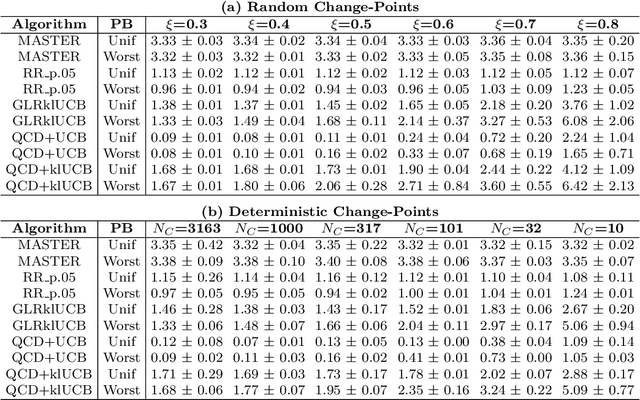
We study the problem of Non-Stationary Reinforcement Learning (NS-RL) without prior knowledge about the system's non-stationarity. A state-of-the-art, black-box algorithm, known as MASTER, is considered, with a focus on identifying the conditions under which it can achieve its stated goals. Specifically, we prove that MASTER's non-stationarity detection mechanism is not triggered for practical choices of horizon, leading to performance akin to a random restarting algorithm. Moreover, we show that the regret bound for MASTER, while being order optimal, stays above the worst-case linear regret until unreasonably large values of the horizon. To validate these observations, MASTER is tested for the special case of piecewise stationary multi-armed bandits, along with methods that employ random restarting, and others that use quickest change detection to restart. A simple, order optimal random restarting algorithm, that has prior knowledge of the non-stationarity is proposed as a baseline. The behavior of the MASTER algorithm is validated in simulations, and it is shown that methods employing quickest change detection are more robust and consistently outperform MASTER and other random restarting approaches.