 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMathKG: The automated mathematical knowledge graph based on LLM and vector database
May 19, 2025A mathematical knowledge graph (KG) presents knowledge within the field of mathematics in a structured manner. Constructing a math KG using natural language is an essential but challenging task. There are two major limitations of existing works: first, they are constrained by corpus completeness, often discarding or manually supplementing incomplete knowledge; second, they typically fail to fully automate the integration of diverse knowledge sources. This paper proposes AutoMathKG, a high-quality, wide-coverage, and multi-dimensional math KG capable of automatic updates. AutoMathKG regards mathematics as a vast directed graph composed of Definition, Theorem, and Problem entities, with their reference relationships as edges. It integrates knowledge from ProofWiki, textbooks, arXiv papers, and TheoremQA, enhancing entities and relationships with large language models (LLMs) via in-context learning for data augmentation. To search for similar entities, MathVD, a vector database, is built through two designed embedding strategies using SBERT. To automatically update, two mechanisms are proposed. For knowledge completion mechanism, Math LLM is developed to interact with AutoMathKG, providing missing proofs or solutions. For knowledge fusion mechanism, MathVD is used to retrieve similar entities, and LLM is used to determine whether to merge with a candidate or add as a new entity. A wide range of experiments demonstrate the advanced performance and broad applicability of the AutoMathKG system, including superior reachability query results in MathVD compared to five baselines and robust mathematical reasoning capability in Math LLM.
Uncertainty-Aware Multi-View Representation Learning
Jan 15, 2022
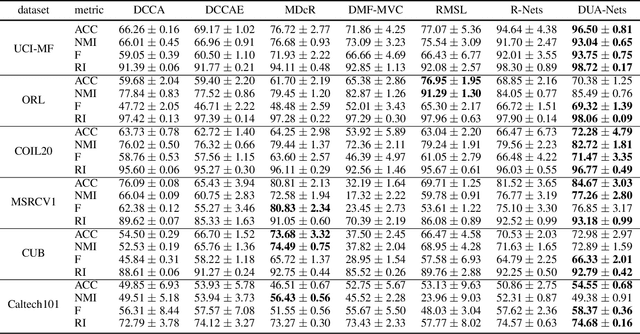
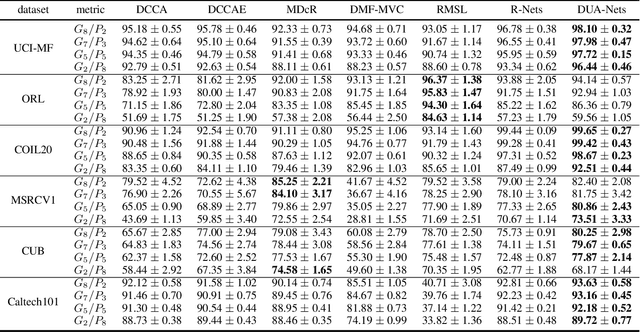

Learning from different data views by exploring the underlying complementary information among them can endow the representation with stronger expressive ability. However, high-dimensional features tend to contain noise, and furthermore, the quality of data usually varies for different samples (even for different views), i.e., one view may be informative for one sample but not the case for another. Therefore, it is quite challenging to integrate multi-view noisy data under unsupervised setting. Traditional multi-view methods either simply treat each view with equal importance or tune the weights of different views to fixed values, which are insufficient to capture the dynamic noise in multi-view data. In this work, we devise a novel unsupervised multi-view learning approach, termed as Dynamic Uncertainty-Aware Networks (DUA-Nets). Guided by the uncertainty of data estimated from the generation perspective, intrinsic information from multiple views is integrated to obtain noise-free representations. Under the help of uncertainty, DUA-Nets weigh each view of individual sample according to data quality so that the high-quality samples (or views) can be fully exploited while the effects from the noisy samples (or views) will be alleviated. Our model achieves superior performance in extensive experiments and shows the robustness to noisy data.
Memory-Efficient Factorization Machines via Binarizing both Data and Model Coefficients
Aug 17, 2021


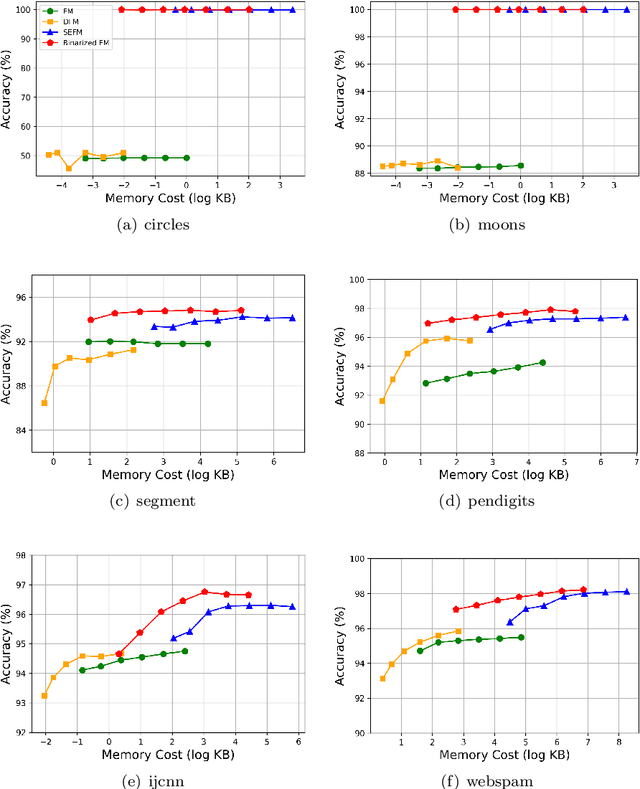
Factorization Machines (FM), a general predictor that can efficiently model feature interactions in linear time, was primarily proposed for collaborative recommendation and have been broadly used for regression, classification and ranking tasks. Subspace Encoding Factorization Machine (SEFM) has been proposed recently to overcome the expressiveness limitation of Factorization Machines (FM) by applying explicit nonlinear feature mapping for both individual features and feature interactions through one-hot encoding to each input feature. Despite the effectiveness of SEFM, it increases the memory cost of FM by $b$ times, where $b$ is the number of bins when applying one-hot encoding on each input feature. To reduce the memory cost of SEFM, we propose a new method called Binarized FM which constraints the model parameters to be binary values (i.e., 1 or $-1$). Then each parameter value can be efficiently stored in one bit. Our proposed method can significantly reduce the memory cost of SEFM model. In addition, we propose a new algorithm to effectively and efficiently learn proposed FM with binary constraints using Straight Through Estimator (STE) with Adaptive Gradient Descent (Adagrad). Finally, we evaluate the performance of our proposed method on eight different classification datasets. Our experimental results have demonstrated that our proposed method achieves comparable accuracy with SEFM but with much less memory cost.