 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Just-in-Time Adaptive Feedback: Enhancing Student Learning via Knowledge-Grounded LLM
May 26, 2026Educational interventions are effective tools for enhancing student learning. While Large Language Models (LLMs) allow for generating adaptive feedback at scale, current studies lack clear methodologies for providing Just-in-Time (JiT) feedback in authentic instructional settings. In this paper, we present a framework that provides adaptive feedback by grounding LLMs with domain-specific expert knowledge. Our approach collects written reasoning logic (strategy essays) from students, analyzes potential error types based on the content of that reasoning, and delivers non-intrusive feedback designed to clarify missing or incorrect concepts. We deploy this framework in a large-scale university course (N > 1000), where it improved student performance by over 80% compared to previous semesters. Lastly, we validate the framework's pedagogical utility by analyzing the learning trajectories; we demonstrate how iterative conversations with LLM facilitate shifting one's misconception to correct understanding.
Towards Characterizing Subjectivity of Individuals through Modeling Value Conflicts and Trade-offs
Apr 17, 2025Large Language Models (LLMs) not only have solved complex reasoning problems but also exhibit remarkable performance in tasks that require subjective decision making. Existing studies suggest that LLM generations can be subjectively grounded to some extent, yet exploring whether LLMs can account for individual-level subjectivity has not been sufficiently studied. In this paper, we characterize subjectivity of individuals on social media and infer their moral judgments using LLMs. We propose a framework, SOLAR (Subjective Ground with Value Abstraction), that observes value conflicts and trade-offs in the user-generated texts to better represent subjective ground of individuals. Empirical results show that our framework improves overall inference results as well as performance on controversial situations. Additionally, we qualitatively show that SOLAR provides explanations about individuals' value preferences, which can further account for their judgments.
Learning to Reduce: Towards Improving Performance of Large Language Models on Structured Data
Jul 03, 2024



Large Language Models (LLMs) have been achieving competent performance on a wide range of downstream tasks, yet existing work shows that inference on structured data is challenging for LLMs. This is because LLMs need to either understand long structured data or select the most relevant evidence before inference, and both approaches are not trivial. This paper proposes a framework, Learning to Reduce, that fine-tunes a language model with On-Policy Learning to generate a reduced version of an input structured data. When compared to state-of-the-art LLMs like GPT-4, Learning to Reduce not only achieves outstanding performance in reducing the input, but shows generalizability on different datasets. We further show that the model fine-tuned with our framework helps LLMs better perform on table QA tasks especially when the context is longer.
Towards Understanding Counseling Conversations: Domain Knowledge and Large Language Models
Feb 22, 2024

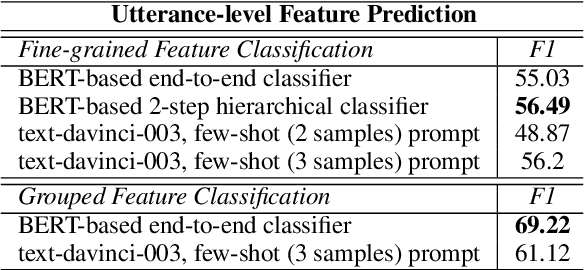

Understanding the dynamics of counseling conversations is an important task, yet it is a challenging NLP problem regardless of the recent advance of Transformer-based pre-trained language models. This paper proposes a systematic approach to examine the efficacy of domain knowledge and large language models (LLMs) in better representing conversations between a crisis counselor and a help seeker. We empirically show that state-of-the-art language models such as Transformer-based models and GPT models fail to predict the conversation outcome. To provide richer context to conversations, we incorporate human-annotated domain knowledge and LLM-generated features; simple integration of domain knowledge and LLM features improves the model performance by approximately 15%. We argue that both domain knowledge and LLM-generated features can be exploited to better characterize counseling conversations when they are used as an additional context to conversations.
Learning to Reduce: Optimal Representations of Structured Data in Prompting Large Language Models
Feb 22, 2024



Large Language Models (LLMs) have been widely used as general-purpose AI agents showing comparable performance on many downstream tasks. However, existing work shows that it is challenging for LLMs to integrate structured data (e.g. KG, tables, DBs) into their prompts; LLMs need to either understand long text data or select the most relevant evidence prior to inference, and both approaches are not trivial. In this paper, we propose a framework, Learning to Reduce, that fine-tunes a language model to generate a reduced version of an input context, given a task description and context input. The model learns to reduce the input context using On-Policy Reinforcement Learning and aims to improve the reasoning performance of a fixed LLM. Experimental results illustrate that our model not only achieves comparable accuracies in selecting the relevant evidence from an input context, but also shows generalizability on different datasets. We further show that our model helps improve the LLM's performance on downstream tasks especially when the context is long.
Towards Explaining Subjective Ground of Individuals on Social Media
Nov 18, 2022Large-scale language models have been reducing the gap between machines and humans in understanding the real world, yet understanding an individual's theory of mind and behavior from text is far from being resolved. This research proposes a neural model -- Subjective Ground Attention -- that learns subjective grounds of individuals and accounts for their judgments on situations of others posted on social media. Using simple attention modules as well as taking one's previous activities into consideration, we empirically show that our model provides human-readable explanations of an individual's subjective preference in judging social situations. We further qualitatively evaluate the explanations generated by the model and claim that our model learns an individual's subjective orientation towards abstract moral concepts
Comparative Studies of Detecting Abusive Language on Twitter
Aug 30, 2018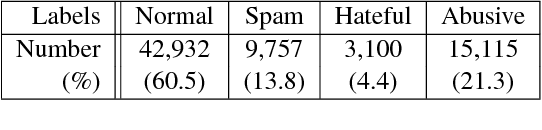

The context-dependent nature of online aggression makes annotating large collections of data extremely difficult. Previously studied datasets in abusive language detection have been insufficient in size to efficiently train deep learning models. Recently, Hate and Abusive Speech on Twitter, a dataset much greater in size and reliability, has been released. However, this dataset has not been comprehensively studied to its potential. In this paper, we conduct the first comparative study of various learning models on Hate and Abusive Speech on Twitter, and discuss the possibility of using additional features and context data for improvements. Experimental results show that bidirectional GRU networks trained on word-level features, with Latent Topic Clustering modules, is the most accurate model scoring 0.805 F1.