 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Discriminative Pattern Mining in Hybrid Domains
Aug 15, 2019


Discriminative pattern mining is a data mining task in which we find patterns that distinguish transactions in the class of interest from those in other classes, and is also called emerging pattern mining or subgroup discovery. One practical problem in discriminative pattern mining is how to handle numeric values in the input dataset. In this paper, we propose an algorithm for discriminative pattern mining that can deal with a transactional dataset in a hybrid domain, i.e. the one that includes both symbolic and numeric values. We also show the execution results of a prototype implementation of the proposed algorithm for two standard benchmark datasets.
A Logic-based Approach to Generatively Defined Discriminative Modeling
Oct 15, 2014
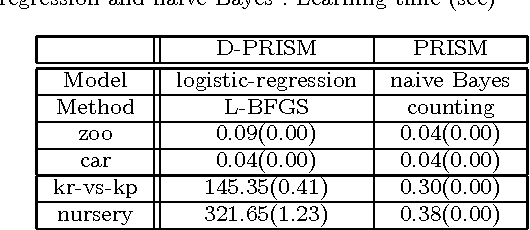
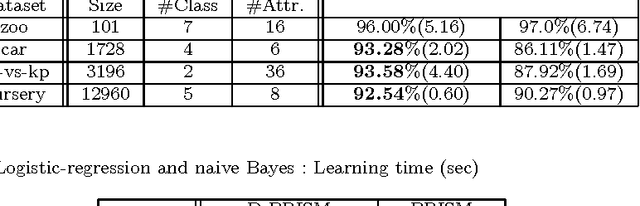

Conditional random fields (CRFs) are usually specified by graphical models but in this paper we propose to use probabilistic logic programs and specify them generatively. Our intension is first to provide a unified approach to CRFs for complex modeling through the use of a Turing complete language and second to offer a convenient way of realizing generative-discriminative pairs in machine learning to compare generative and discriminative models and choose the best model. We implemented our approach as the D-PRISM language by modifying PRISM, a logic-based probabilistic modeling language for generative modeling, while exploiting its dynamic programming mechanism for efficient probability computation. We tested D-PRISM with logistic regression, a linear-chain CRF and a CRF-CFG and empirically confirmed their excellent discriminative performance compared to their generative counterparts, i.e.\ naive Bayes, an HMM and a PCFG. We also introduced new CRF models, CRF-BNCs and CRF-LCGs. They are CRF versions of Bayesian network classifiers and probabilistic left-corner grammars respectively and easily implementable in D-PRISM. We empirically showed that they outperform their generative counterparts as expected.
Verbal Characterization of Probabilistic Clusters using Minimal Discriminative Propositions
Aug 31, 2011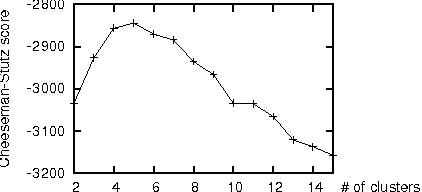
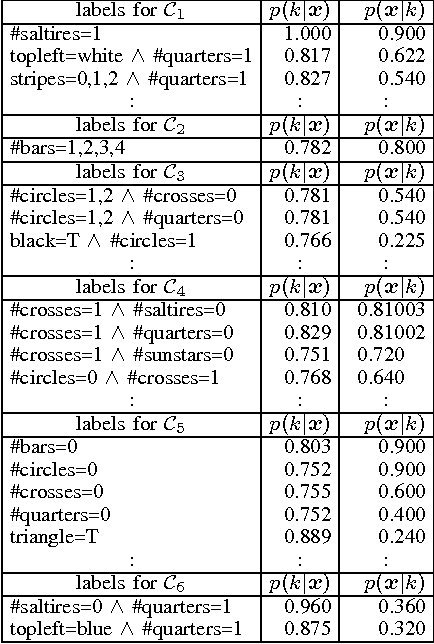
In a knowledge discovery process, interpretation and evaluation of the mined results are indispensable in practice. In the case of data clustering, however, it is often difficult to see in what aspect each cluster has been formed. This paper proposes a method for automatic and objective characterization or "verbalization" of the clusters obtained by mixture models, in which we collect conjunctions of propositions (attribute-value pairs) that help us interpret or evaluate the clusters. The proposed method provides us with a new, in-depth and consistent tool for cluster interpretation/evaluation, and works for various types of datasets including continuous attributes and missing values. Experimental results with a couple of standard datasets exhibit the utility of the proposed method, and the importance of the feedbacks from the interpretation/evaluation step.
CHR(PRISM)-based Probabilistic Logic Learning
Jul 22, 2010
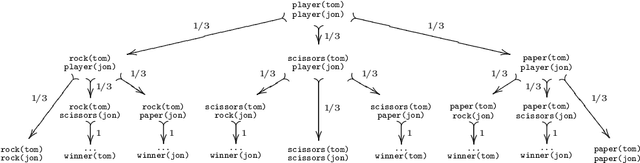
PRISM is an extension of Prolog with probabilistic predicates and built-in support for expectation-maximization learning. Constraint Handling Rules (CHR) is a high-level programming language based on multi-headed multiset rewrite rules. In this paper, we introduce a new probabilistic logic formalism, called CHRiSM, based on a combination of CHR and PRISM. It can be used for high-level rapid prototyping of complex statistical models by means of "chance rules". The underlying PRISM system can then be used for several probabilistic inference tasks, including probability computation and parameter learning. We define the CHRiSM language in terms of syntax and operational semantics, and illustrate it with examples. We define the notion of ambiguous programs and define a distribution semantics for unambiguous programs. Next, we describe an implementation of CHRiSM, based on CHR(PRISM). We discuss the relation between CHRiSM and other probabilistic logic programming languages, in particular PCHR. Finally we identify potential application domains.