 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Self-Supervised Terrain Type Discovery for Mobile Platforms
Oct 13, 2020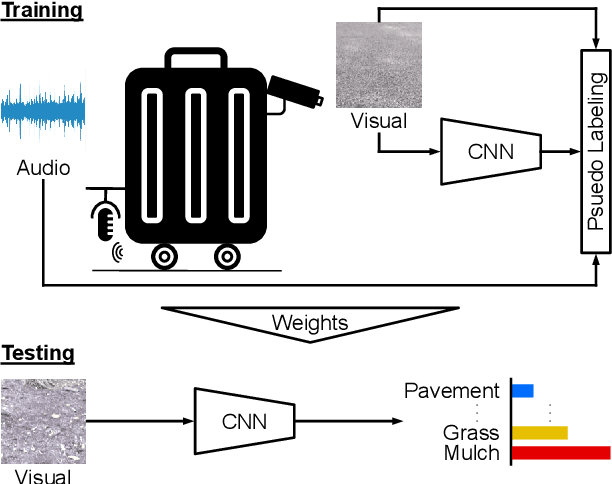

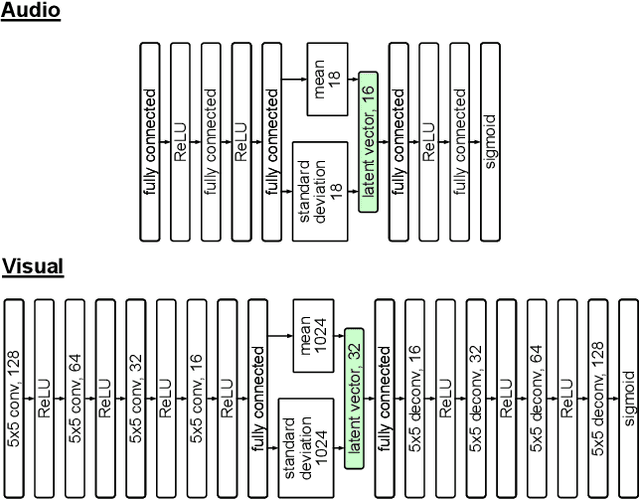

The ability to both recognize and discover terrain characteristics is an important function required for many autonomous ground robots such as social robots, assistive robots, autonomous vehicles, and ground exploration robots. Recognizing and discovering terrain characteristics is challenging because similar terrains may have very different appearances (e.g., carpet comes in many colors), while terrains with very similar appearance may have very different physical properties (e.g. mulch versus dirt). In order to address the inherent ambiguity in vision-based terrain recognition and discovery, we propose a multi-modal self-supervised learning technique that switches between audio features extracted from a mic attached to the underside of a mobile platform and image features extracted by a camera on the platform to cluster terrain types. The terrain cluster labels are then used to train an image-based convolutional neural network to predict changes in terrain types. Through experiments, we demonstrate that the proposed self-supervised terrain type discovery method achieves over 80% accuracy, which greatly outperforms several baselines and suggests strong potential for assistive applications.
Incremental Class Discovery for Semantic Segmentation with RGBD Sensing
Jul 23, 2019

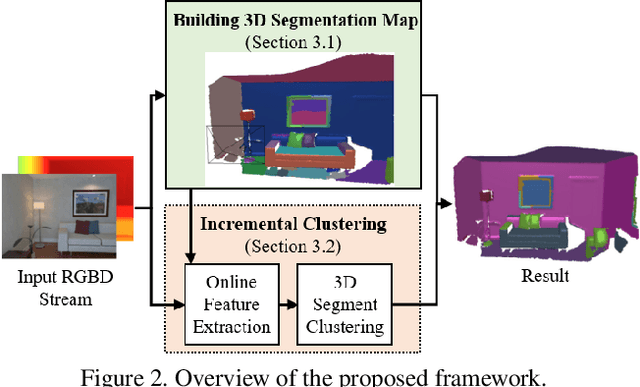

This work addresses the task of open world semantic segmentation using RGBD sensing to discover new semantic classes over time. Although there are many types of objects in the real-word, current semantic segmentation methods make a closed world assumption and are trained only to segment a limited number of object classes. Towards a more open world approach, we propose a novel method that incrementally learns new classes for image segmentation. The proposed system first segments each RGBD frame using both color and geometric information, and then aggregates that information to build a single segmented dense 3D map of the environment. The segmented 3D map representation is a key component of our approach as it is used to discover new object classes by identifying coherent regions in the 3D map that have no semantic label. The use of coherent region in the 3D map as a primitive element, rather than traditional elements such as surfels or voxels, also significantly reduces the computational complexity and memory use of our method. It thus leads to semi-real-time performance at {10.7}Hz when incrementally updating the dense 3D map at every frame. Through experiments on the NYUDv2 dataset, we demonstrate that the proposed method is able to correctly cluster objects of both known and unseen classes. We also show the quantitative comparison with the state-of-the-art supervised methods, the processing time of each step, and the influences of each component.
Fast and Accurate Semantic Mapping through Geometric-based Incremental Segmentation
Mar 07, 2018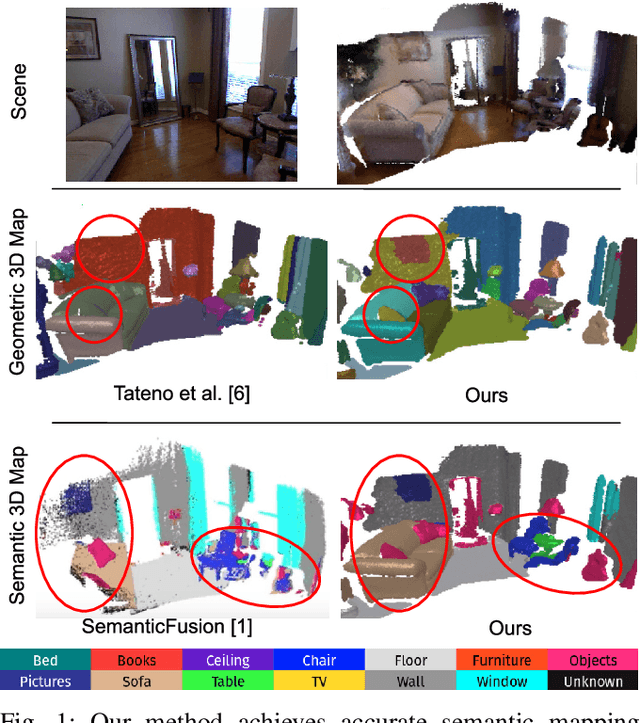
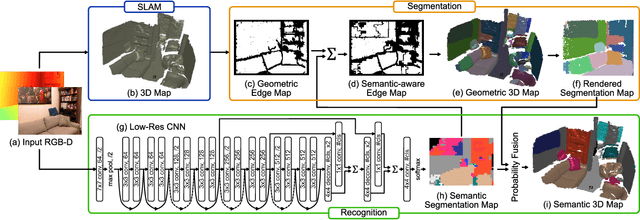

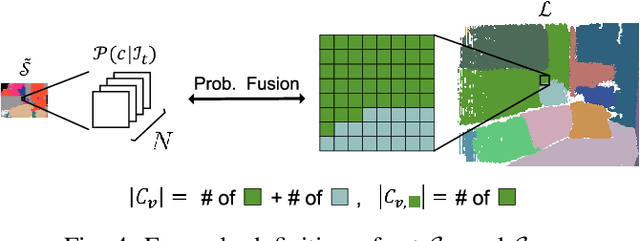
We propose an efficient and scalable method for incrementally building a dense, semantically annotated 3D map in real-time. The proposed method assigns class probabilities to each region, not each element (e.g., surfel and voxel), of the 3D map which is built up through a robust SLAM framework and incrementally segmented with a geometric-based segmentation method. Differently from all other approaches, our method has a capability of running at over 30Hz while performing all processing components, including SLAM, segmentation, 2D recognition, and updating class probabilities of each segmentation label at every incoming frame, thanks to the high efficiency that characterizes the computationally intensive stages of our framework. By utilizing a specifically designed CNN to improve the frame-wise segmentation result, we can also achieve high accuracy. We validate our method on the NYUv2 dataset by comparing with the state of the art in terms of accuracy and computational efficiency, and by means of an analysis in terms of time and space complexity.