 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPOI: Listwise Preference Optimization for Vision Language Models
May 27, 2025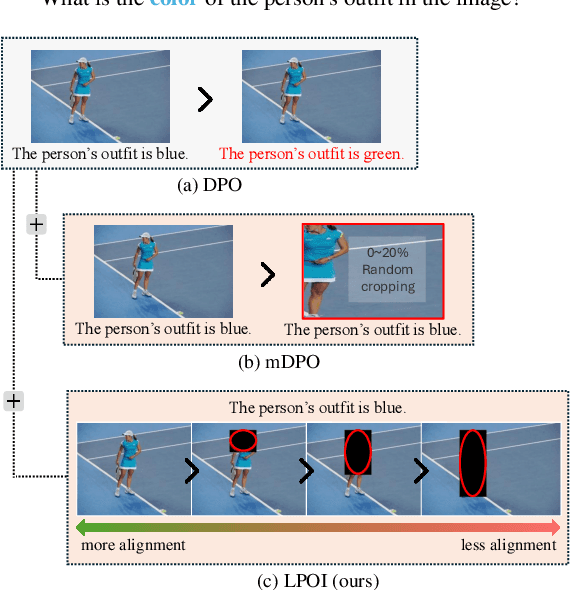
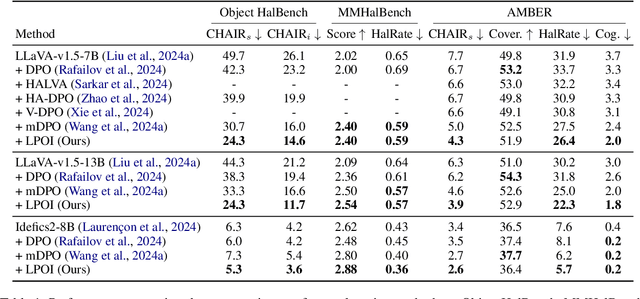
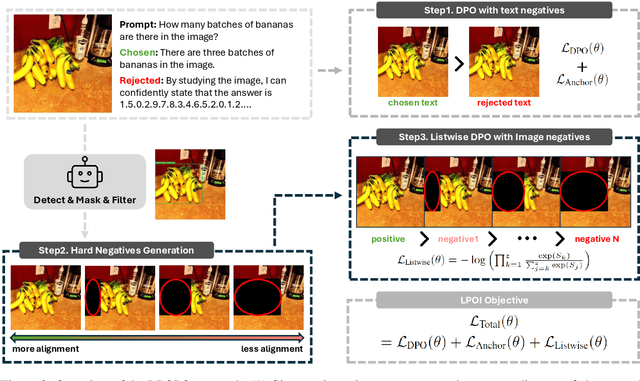

Aligning large VLMs with human preferences is a challenging task, as methods like RLHF and DPO often overfit to textual information or exacerbate hallucinations. Although augmenting negative image samples partially addresses these pitfalls, no prior work has employed listwise preference optimization for VLMs, due to the complexity and cost of constructing listwise image samples. In this work, we propose LPOI, the first object-aware listwise preference optimization developed for reducing hallucinations in VLMs. LPOI identifies and masks a critical object in the image, and then interpolates the masked region between the positive and negative images to form a sequence of incrementally more complete images. The model is trained to rank these images in ascending order of object visibility, effectively reducing hallucinations while retaining visual fidelity. LPOI requires no extra annotations beyond standard pairwise preference data, as it automatically constructs the ranked lists through object masking and interpolation. Comprehensive experiments on MMHalBench, AMBER, and Object HalBench confirm that LPOI outperforms existing preference optimization methods in reducing hallucinations and enhancing VLM performance. We make the code available at https://github.com/fatemehpesaran310/lpoi.
Learning to Arbitrate Human and Robot Control using Disagreement between Sub-Policies
Aug 24, 2021
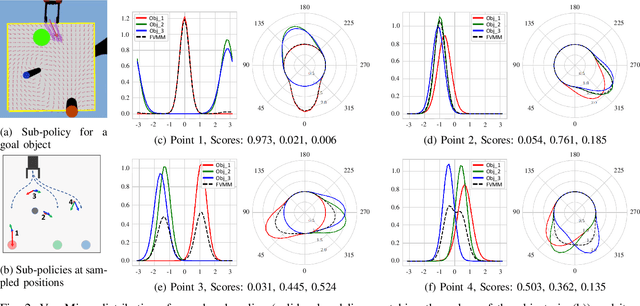
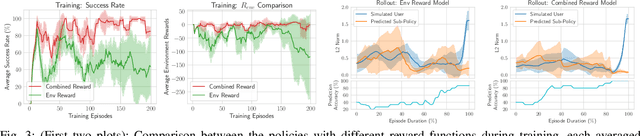
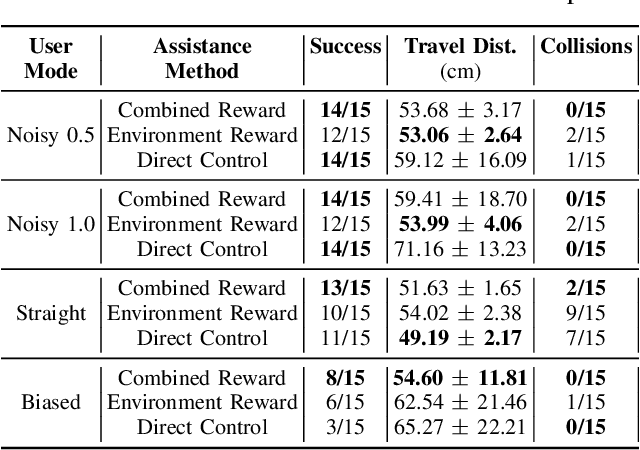
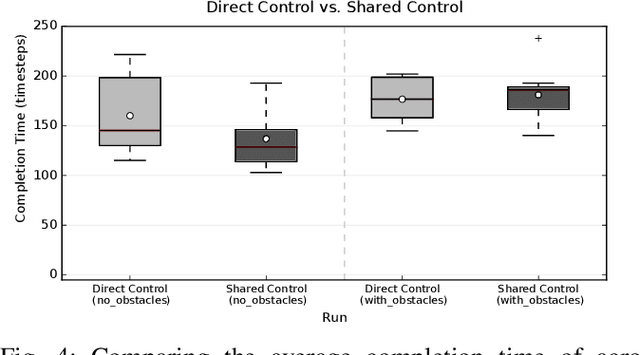
In the context of teleoperation, arbitration refers to deciding how to blend between human and autonomous robot commands. We present a reinforcement learning solution that learns an optimal arbitration strategy that allocates more control authority to the human when the robot comes across a decision point in the task. A decision point is where the robot encounters multiple options (sub-policies), such as having multiple paths to get around an obstacle or deciding between two candidate goals. By expressing each directional sub-policy as a von Mises distribution, we identify the decision points by observing the modality of the mixture distribution. Our reward function reasons on this modality and prioritizes to match its learned policy to either the user or the robot accordingly. We report teleoperation experiments on reach-and-grasping objects using a robot manipulator arm with different simulated human controllers. Results indicate that our shared control agent outperforms direct control and improves the teleoperation performance among different users. Using our reward term enables flexible blending between human and robot commands while maintaining safe and accurate teleoperation.
A System for Traded Control Teleoperation of Manipulation Tasks using Intent Prediction from Hand Gestures
Jul 05, 2021

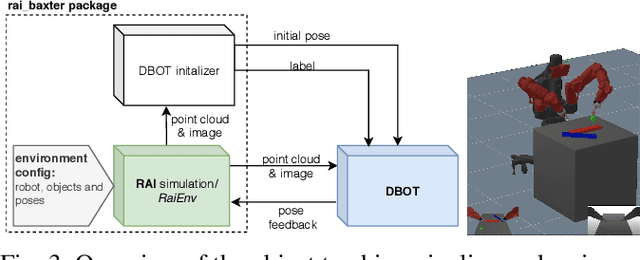
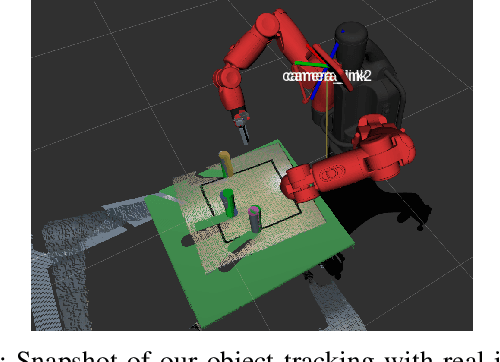
This paper presents a teleoperation system that includes robot perception and intent prediction from hand gestures. The perception module identifies the objects present in the robot workspace and the intent prediction module which object the user likely wants to grasp. This architecture allows the approach to rely on traded control instead of direct control: we use hand gestures to specify the goal objects for a sequential manipulation task, the robot then autonomously generates a grasping or a retrieving motion using trajectory optimization. The perception module relies on the model-based tracker to precisely track the 6D pose of the objects and makes use of a state of the art learning-based object detection and segmentation method, to initialize the tracker by automatically detecting objects in the scene. Goal objects are identified from user hand gestures using a trained a multi-layer perceptron classifier. After presenting all the components of the system and their empirical evaluation, we present experimental results comparing our pipeline to a direct traded control approach (i.e., one that does not use prediction) which shows that using intent prediction allows to bring down the overall task execution time.
Natural Gradient Shared Control
Jul 30, 2020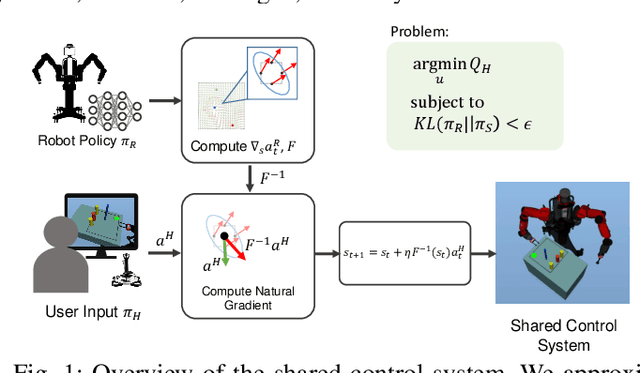
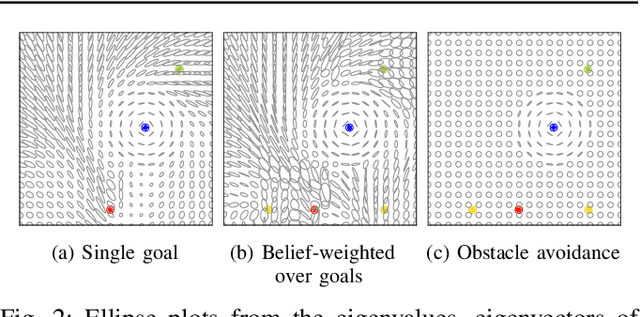
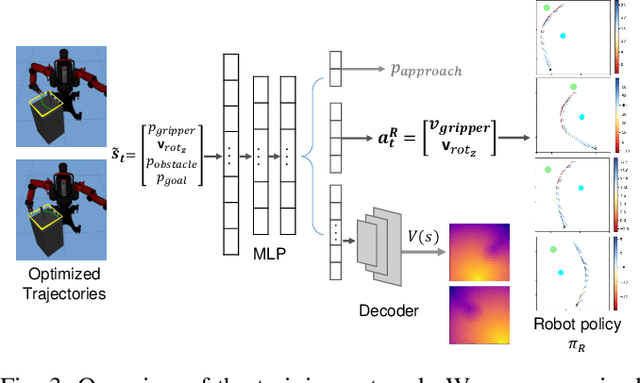

We propose a formalism for shared control, which is the problem of defining a policy that blends user control and autonomous control. The challenge posed by the shared autonomy system is to maintain user control authority while allowing the robot to support the user. This can be done by enforcing constraints or acting optimally when the intent is clear. Our proposed solution relies on natural gradients emerging from the divergence constraint between the robot and the shared policy. We approximate the Fisher information by sampling a learned robot policy and computing the local gradient to augment the user control when necessary. A user study performed on a manipulation task demonstrates that our approach allows for more efficient task completion while keeping control authority against a number of baseline methods.
Learning Arbitration for Shared Autonomy by Hindsight Data Aggregation
Jun 28, 2019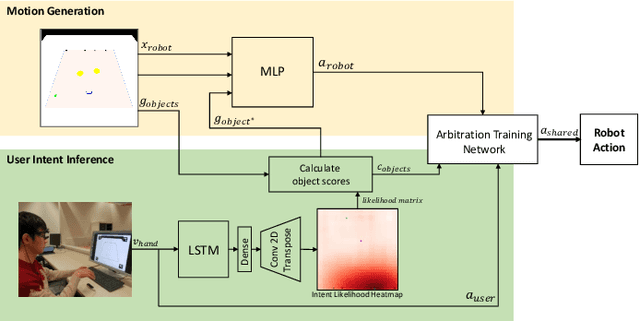
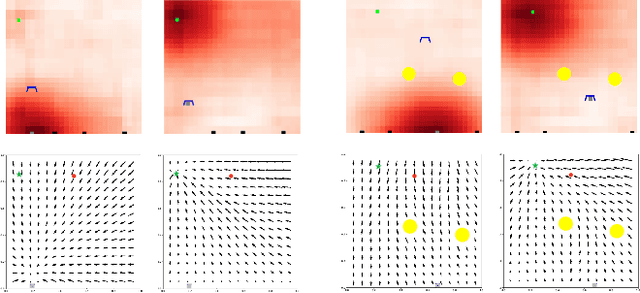

In this paper we present a framework for the teleoperation of pick-and-place tasks. We define a shared control policy that allows to blend between direct user control and autonomous control based on user intent inference. One of the main challenges in shared autonomy systems is to define the arbitration function, which decides when to let the autonomous agent take over. In this work, we propose a model and training method to learn the arbitration function. Our model is based on a recurrent neural network that takes as input the state, intent prediction scores and user command to produce an arbitration between user and robot commands. This work extends our previous work on differentiable policies for shared autonomy. Differentiability of the policy is desirable to further train the shared autonomy system end-to-end. In this work we propose training of the arbitration function by using data from user performing the task with shared control. We present initial results by teleoperating a gripper in a virtual environment using pre-trained motion generation and intent prediction. We compare our data aggregation training procedure to a handcrafted arbitration function. Our preliminary results show the efficacy of the approach and shed light on limitations that we believe demonstrate the need for user adaptability in shared autonomy systems.