 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Gradient Shared Control
Paper and Code
Jul 30, 2020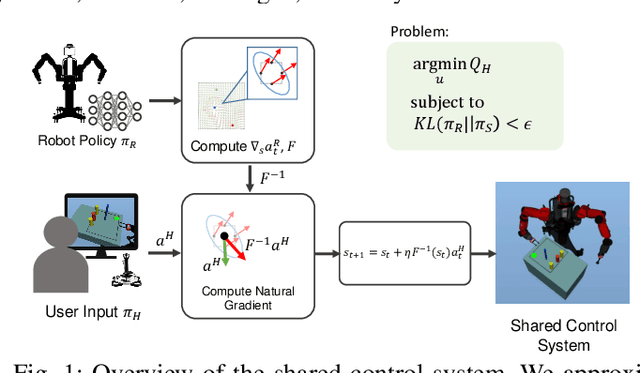
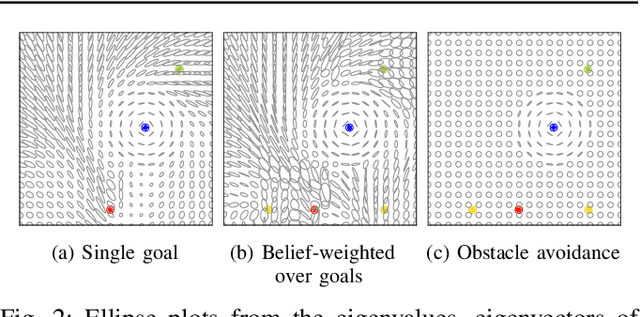
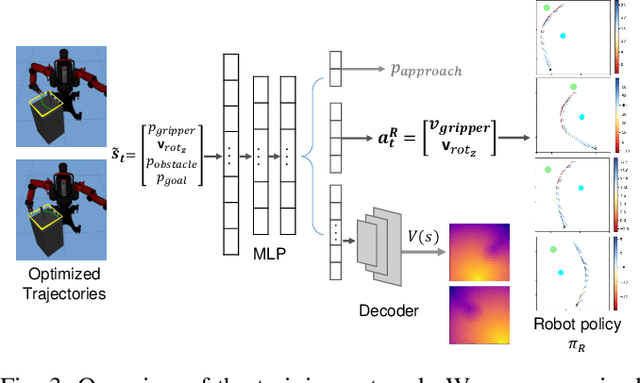

We propose a formalism for shared control, which is the problem of defining a policy that blends user control and autonomous control. The challenge posed by the shared autonomy system is to maintain user control authority while allowing the robot to support the user. This can be done by enforcing constraints or acting optimally when the intent is clear. Our proposed solution relies on natural gradients emerging from the divergence constraint between the robot and the shared policy. We approximate the Fisher information by sampling a learned robot policy and computing the local gradient to augment the user control when necessary. A user study performed on a manipulation task demonstrates that our approach allows for more efficient task completion while keeping control authority against a number of baseline methods.