 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYouTube-GDD: A challenging gun detection dataset with rich contextual information
Mar 08, 2022
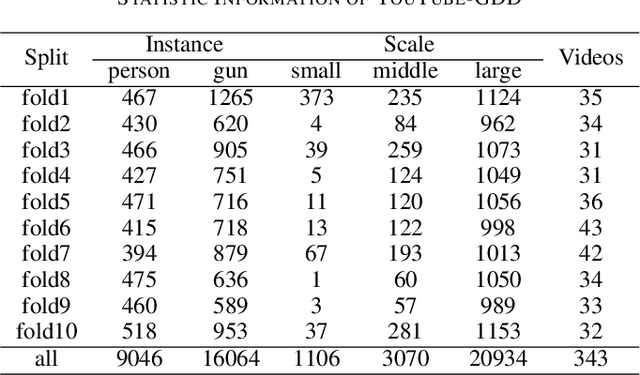
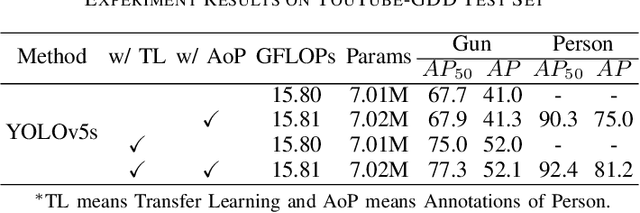
An automatic gun detection system can detect potential gun-related violence at an early stage that is of paramount importance for citizens security. In the whole system, object detection algorithm is the key to perceive the environment so that the system can detect dangerous objects such as pistols and rifles. However, mainstream deep learning-based object detection algorithms depend heavily on large-scale high-quality annotated samples, and the existing gun datasets are characterized by low resolution, little contextual information and little data volume. To promote the development of security, this work presents a new challenging dataset called YouTube Gun Detection Dataset (YouTube-GDD). Our dataset is collected from 343 high-definition YouTube videos and contains 5000 well-chosen images, in which 16064 instances of gun and 9046 instances of person are annotated. Compared to other datasets, YouTube-GDD is "dynamic", containing rich contextual information and recording shape changes of the gun during shooting. To build a baseline for gun detection, we evaluate YOLOv5 on YouTube-GDD and analyze the influence of additional related annotated information on gun detection. YouTube-GDD and subsequent updates will be released at https://github.com/UCAS-GYX/YouTube-GDD.
Real-time Streaming Perception System for Autonomous Driving
Jul 30, 2021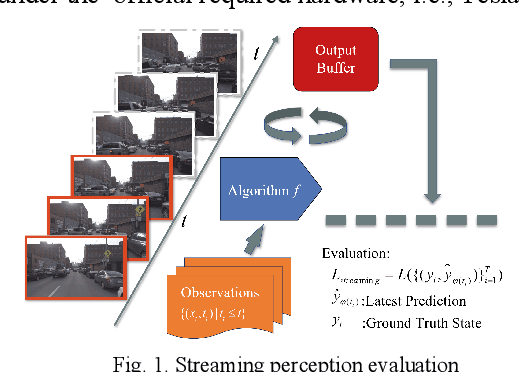
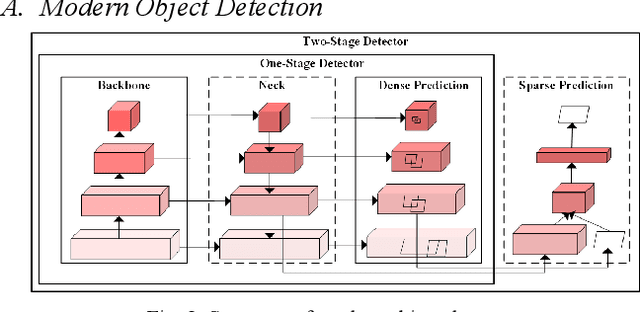
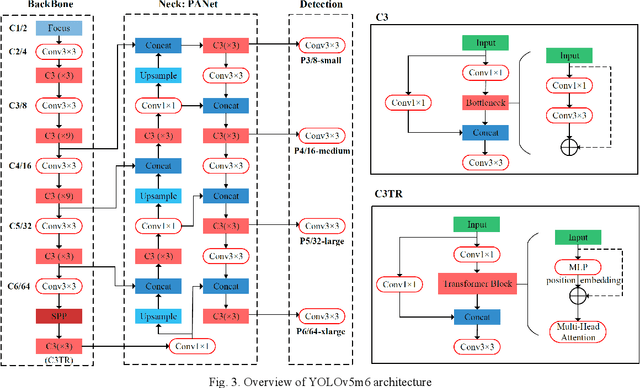
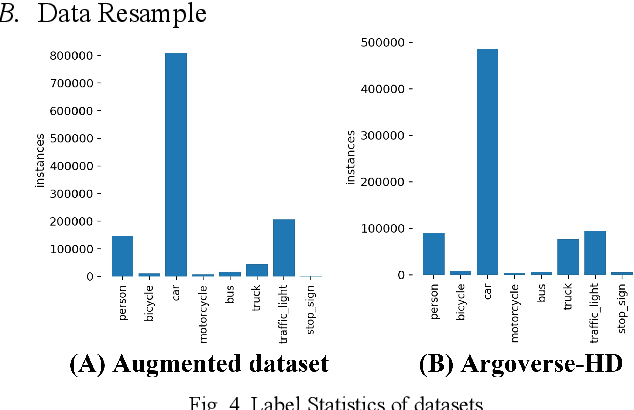
Nowadays, plenty of deep learning technologies are being applied to all aspects of autonomous driving with promising results. Among them, object detection is the key to improve the ability of an autonomous agent to perceive its environment so that it can (re)act. However, previous vision-based object detectors cannot achieve satisfactory performance under real-time driving scenarios. To remedy this, we present the real-time steaming perception system in this paper, which is also the 2nd Place solution of Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) for the detection-only track. Unlike traditional object detection challenges, which focus mainly on the absolute performance, streaming perception task requires achieving a balance of accuracy and latency, which is crucial for real-time autonomous driving. We adopt YOLOv5 as our basic framework, data augmentation, Bag-of-Freebies, and Transformer are adopted to improve streaming object detection performance with negligible extra inference cost. On the Argoverse-HD test set, our method achieves 33.2 streaming AP (34.6 streaming AP verified by the organizer) under the required hardware. Its performance significantly surpasses the fixed baseline of 13.6 (host team), demonstrating the potentiality of application.
Content-Augmented Feature Pyramid Network with Light Linear Transformers
May 20, 2021
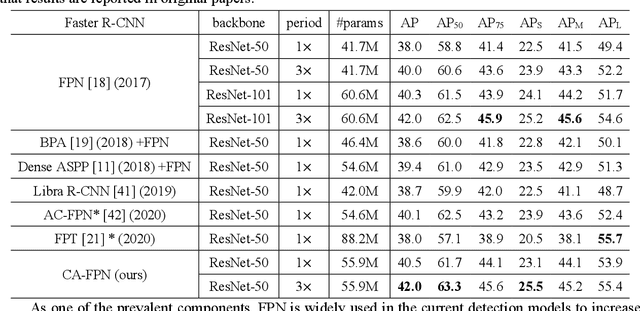
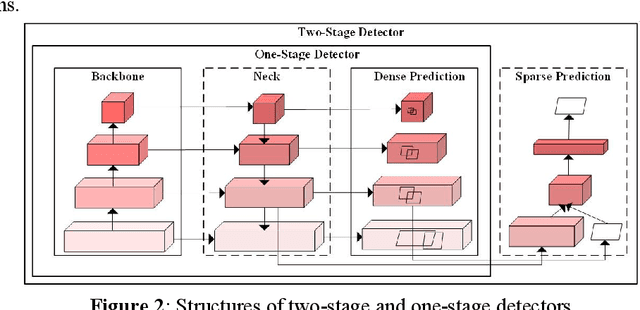
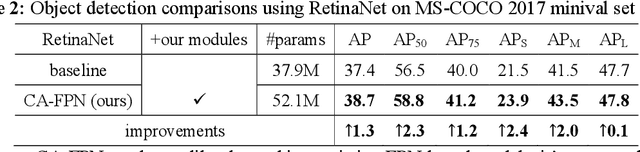
Recently, plenty of work has tried to introduce transformers into computer vision tasks, with good results. Unlike classic convolution networks, which extract features within a local receptive field, transformers can adaptively aggregate similar features from a global view using self-attention mechanism. For object detection, Feature Pyramid Network (FPN) proposes feature interaction across layers and proves its extremely importance. However, its interaction is still in a local manner, which leaves a lot of room for improvement. Since transformer was originally designed for NLP tasks, adapting processing subject directly from text to image will cause unaffordable computation and space overhead. In this paper, we utilize a linearized attention function to overcome above problems and build a novel architecture, named Content-Augmented Feature Pyramid Network (CA-FPN), which proposes a global content extraction module and deeply combines with FPN through light linear transformers. What's more, light transformers can further make the application of multi-head attention mechanism easier. Most importantly, our CA-FPN can be readily plugged into existing FPN-based models. Extensive experiments on the challenging COCO object detection dataset demonstrated that our CA-FPN significantly outperforms competitive baselines without bells and whistles. Code will be made publicly available.