 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-Augmented Feature Pyramid Network with Light Linear Transformers
Paper and Code
May 20, 2021
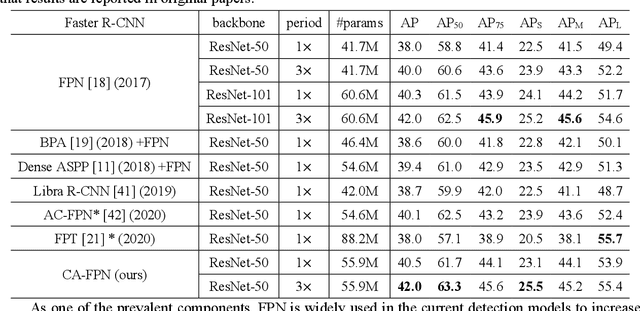
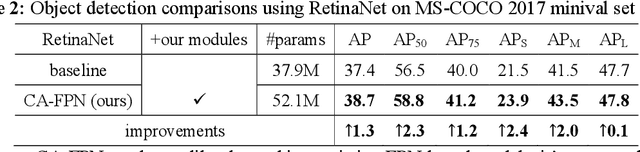
Recently, plenty of work has tried to introduce transformers into computer vision tasks, with good results. Unlike classic convolution networks, which extract features within a local receptive field, transformers can adaptively aggregate similar features from a global view using self-attention mechanism. For object detection, Feature Pyramid Network (FPN) proposes feature interaction across layers and proves its extremely importance. However, its interaction is still in a local manner, which leaves a lot of room for improvement. Since transformer was originally designed for NLP tasks, adapting processing subject directly from text to image will cause unaffordable computation and space overhead. In this paper, we utilize a linearized attention function to overcome above problems and build a novel architecture, named Content-Augmented Feature Pyramid Network (CA-FPN), which proposes a global content extraction module and deeply combines with FPN through light linear transformers. What's more, light transformers can further make the application of multi-head attention mechanism easier. Most importantly, our CA-FPN can be readily plugged into existing FPN-based models. Extensive experiments on the challenging COCO object detection dataset demonstrated that our CA-FPN significantly outperforms competitive baselines without bells and whistles. Code will be made publicly available.