 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropic Mirror Monte Carlo
Feb 03, 2026Importance sampling is a Monte Carlo method which designs estimators of expectations under a target distribution using weighted samples from a proposal distribution. When the target distribution is complex, such as multimodal distributions in highdimensional spaces, the efficiency of importance sampling critically depends on the choice of the proposal distribution. In this paper, we propose a novel adaptive scheme for the construction of efficient proposal distributions. Our algorithm promotes efficient exploration of the target distribution by combining global sampling mechanisms with a delayed weighting procedure. The proposed weighting mechanism plays a key role by enabling rapid resampling in regions where the proposal distribution is poorly adapted to the target. Our sampling algorithm is shown to be geometrically convergent under mild assumptions and is illustrated through various numerical experiments.
A Probabilistic Semi-Supervised Approach with Triplet Markov Chains
Sep 07, 2023Triplet Markov chains are general generative models for sequential data which take into account three kinds of random variables: (noisy) observations, their associated discrete labels and latent variables which aim at strengthening the distribution of the observations and their associated labels. However, in practice, we do not have at our disposal all the labels associated to the observations to estimate the parameters of such models. In this paper, we propose a general framework based on a variational Bayesian inference to train parameterized triplet Markov chain models in a semi-supervised context. The generality of our approach enables us to derive semi-supervised algorithms for a variety of generative models for sequential Bayesian classification.
Expressivity of Hidden Markov Chains vs. Recurrent Neural Networks from a system theoretic viewpoint
Aug 17, 2022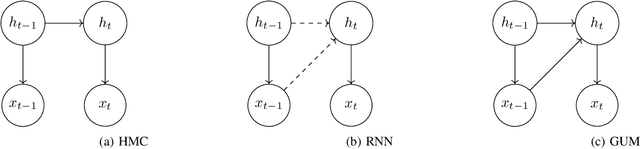

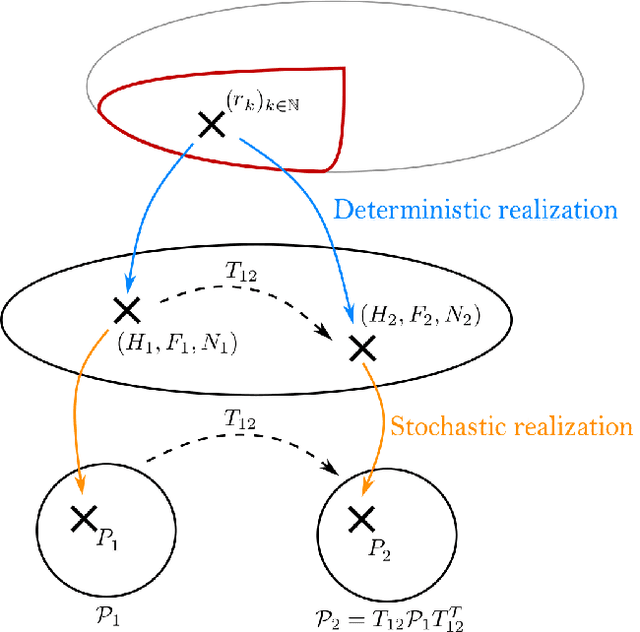
Hidden Markov Chains (HMC) and Recurrent Neural Networks (RNN) are two well known tools for predicting time series. Even though these solutions were developed independently in distinct communities, they share some similarities when considered as probabilistic structures. So in this paper we first consider HMC and RNN as generative models, and we embed both structures in a common generative unified model (GUM). We next address a comparative study of the expressivity of these models. To that end we assume that the models are furthermore linear and Gaussian. The probability distributions produced by these models are characterized by structured covariance series, and as a consequence expressivity reduces to comparing sets of structured covariance series, which enables us to call for stochastic realization theory (SRT). We finally provide conditions under which a given covariance series can be realized by a GUM, an HMC or an RNN.
Combining Federated and Active Learning for Communication-efficient Distributed Failure Prediction in Aeronautics
Jan 21, 2020


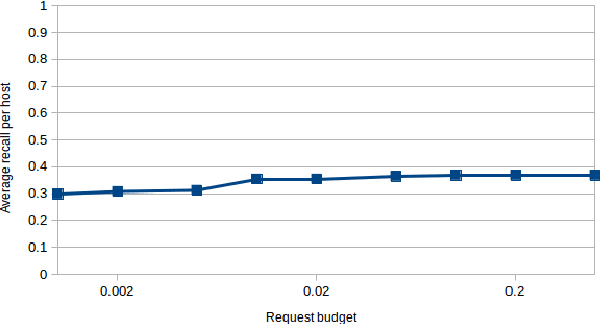
Machine Learning has proven useful in the recent years as a way to achieve failure prediction for industrial systems. However, the high computational resources necessary to run learning algorithms are an obstacle to its widespread application. The sub-field of Distributed Learning offers a solution to this problem by enabling the use of remote resources but at the expense of introducing communication costs in the application that are not always acceptable. In this paper, we propose a distributed learning approach able to optimize the use of computational and communication resources to achieve excellent learning model performances through a centralized architecture. To achieve this, we present a new centralized distributed learning algorithm that relies on the learning paradigms of Active Learning and Federated Learning to offer a communication-efficient method that offers guarantees of model precision on both the clients and the central server. We evaluate this method on a public benchmark and show that its performances in terms of precision are very close to state-of-the-art performance level of non-distributed learning despite additional constraints.