 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiply Robust Causal Mediation Analysis with Continuous Treatments
May 19, 2021In many applications, researchers are interested in the direct and indirect causal effects of an intervention on an outcome of interest. Mediation analysis offers a rigorous framework for the identification and estimation of such causal quantities. In the case of binary treatment, efficient estimators for the direct and indirect effects are derived by Tchetgen Tchetgen and Shpitser (2012). These estimators are based on influence functions and possess desirable multiple robustness properties. However, they are not readily applicable when treatments are continuous, which is the case in several settings, such as drug dosage in medical applications. In this work, we extend the influence function-based estimator of Tchetgen Tchetgen and Shpitser (2012) to deal with continuous treatments by utilizing a kernel smoothing approach. We first demonstrate that our proposed estimator preserves the multiple robustness property of the estimator in Tchetgen Tchetgen and Shpitser (2012). Then we show that under certain mild regularity conditions, our estimator is asymptotically normal. Our estimation scheme allows for high-dimensional nuisance parameters that can be estimated at slower rates than the target parameter. Additionally, we utilize cross-fitting, which allows for weaker smoothness requirements for the nuisance functions.
Inference for BART with Multinomial Outcomes
Jan 18, 2021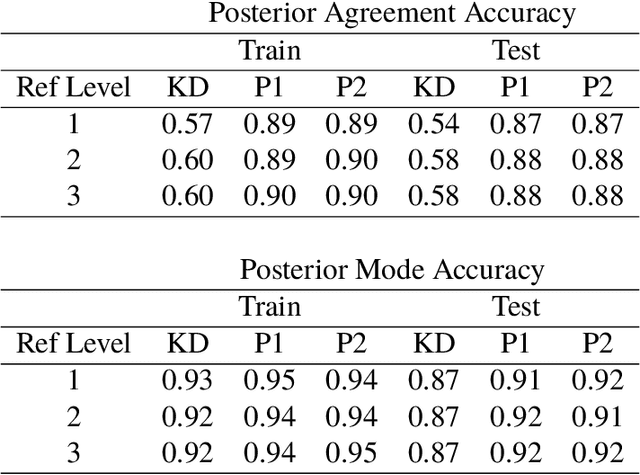
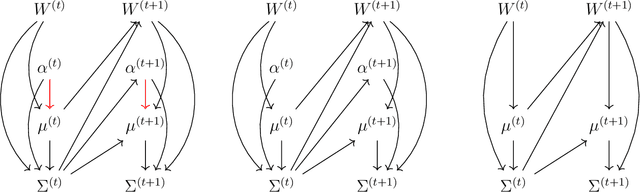
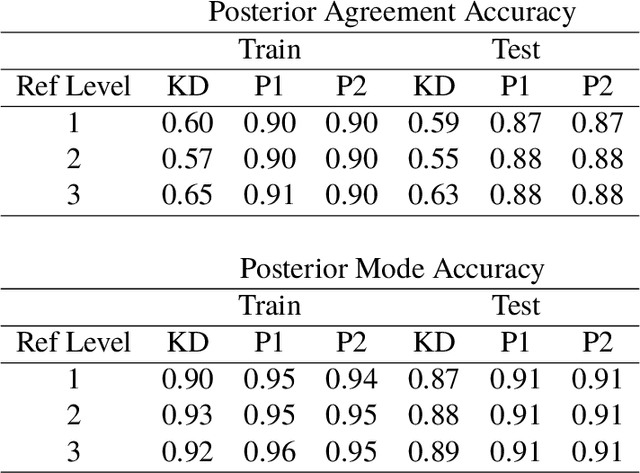
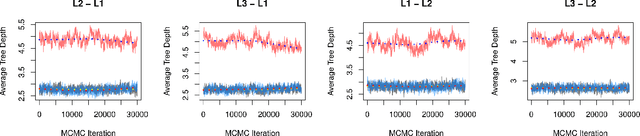
The multinomial probit Bayesian additive regression trees (MPBART) framework was proposed by Kindo et al. (KD), approximating the latent utilities in the multinomial probit (MNP) model with BART (Chipman et al. 2010). Compared to multinomial logistic models, MNP does not assume independent alternatives and the correlation structure among alternatives can be specified through multivariate Gaussian distributed latent utilities. We introduce two new algorithms for fitting the MPBART and show that the theoretical mixing rates of our proposals are equal or superior to the existing algorithm in KD. Through simulations, we explore the robustness of the methods to the choice of reference level, imbalance in outcome frequencies, and the specifications of prior hyperparameters for the utility error term. The work is motivated by the application of generating posterior predictive distributions for mortality and engagement in care among HIV-positive patients based on electronic health records (EHRs) from the Academic Model Providing Access to Healthcare (AMPATH) in Kenya. In both the application and simulations, we observe better performance using our proposals as compared to KD in terms of MCMC convergence rate and posterior predictive accuracy.
Classification using Ensemble Learning under Weighted Misclassification Loss
Dec 16, 2018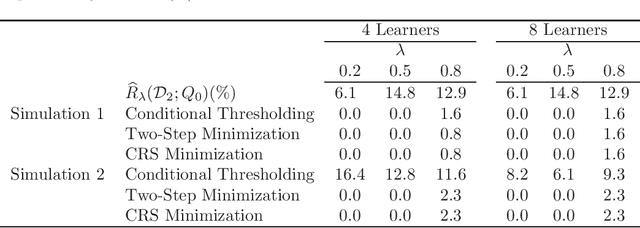
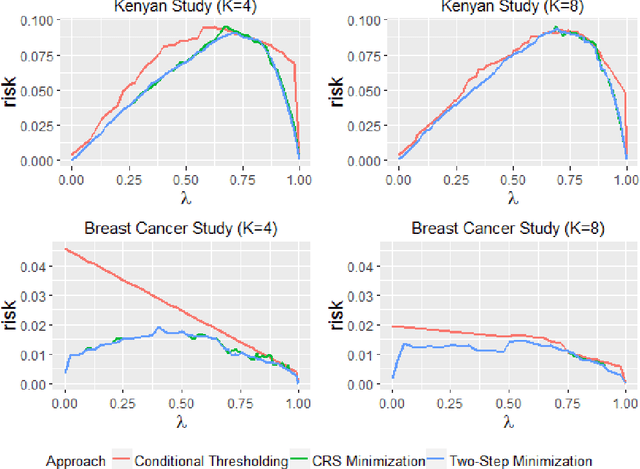
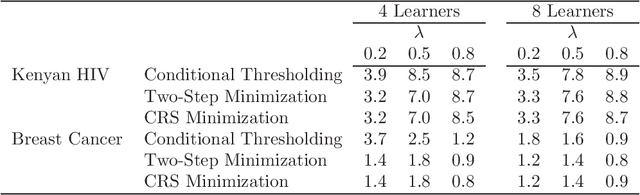

Binary classification rules based on covariates typically depend on simple loss functions such as zero-one misclassification. Some cases may require more complex loss functions. For example, individual-level monitoring of HIV-infected individuals on antiretroviral therapy (ART) requires periodic assessment of treatment failure, defined as having a viral load (VL) value above a certain threshold. In some resource limited settings, VL tests may be limited by cost or technology, and diagnoses are based on other clinical markers. Depending on scenario, higher premium may be placed on avoiding false-positives which brings greater cost and reduced treatment options. Here, the optimal rule is determined by minimizing a weighted misclassification loss/risk. We propose a method for finding and cross-validating optimal binary classification rules under weighted misclassification loss. We focus on rules comprising a prediction score and an associated threshold, where the score is derived using an ensemble learner. Simulations and examples show that our method, which derives the score and threshold jointly, more accurately estimates overall risk and has better operating characteristics compared with methods that derive the score first and the cutoff conditionally on the score especially for finite samples.