 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Guided k-Guard Sampling for Long-Horizon Autoregressive Video Generation
Jan 27, 2026Autoregressive (AR) architectures have achieved significant successes in LLMs, inspiring explorations for video generation. In LLMs, top-p/top-k sampling strategies work exceptionally well: language tokens have high semantic density and low redundancy, so a fixed size of token candidates already strikes a balance between semantic accuracy and generation diversity. In contrast, video tokens have low semantic density and high spatio-temporal redundancy. This mismatch makes static top-k/top-p strategies ineffective for video decoders: they either introduce unnecessary randomness for low-uncertainty regions (static backgrounds) or get stuck in early errors for high-uncertainty regions (foreground objects). Prediction errors will accumulate as more frames are generated and eventually severely degrade long-horizon quality. To address this, we propose Entropy-Guided k-Guard (ENkG) sampling, a simple yet effective strategy that adapts sampling to token-wise dispersion, quantified by the entropy of each token's predicted distribution. ENkG uses adaptive token candidate sizes: for low-entropy regions, it employs fewer candidates to suppress redundant noise and preserve structural integrity; for high-entropy regions, it uses more candidates to mitigate error compounding. ENkG is model-agnostic, training-free, and adds negligible overhead. Experiments demonstrate consistent improvements in perceptual quality and structural stability compared to static top-k/top-p strategies.
Identify treatment effect patterns for personalised decisions
Jun 14, 2019
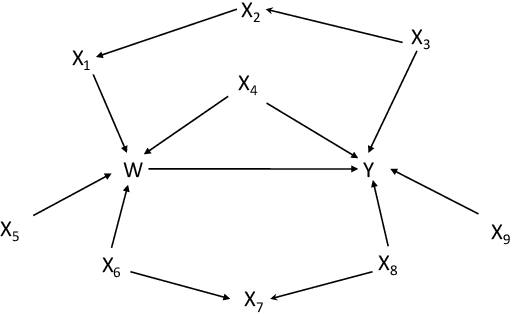
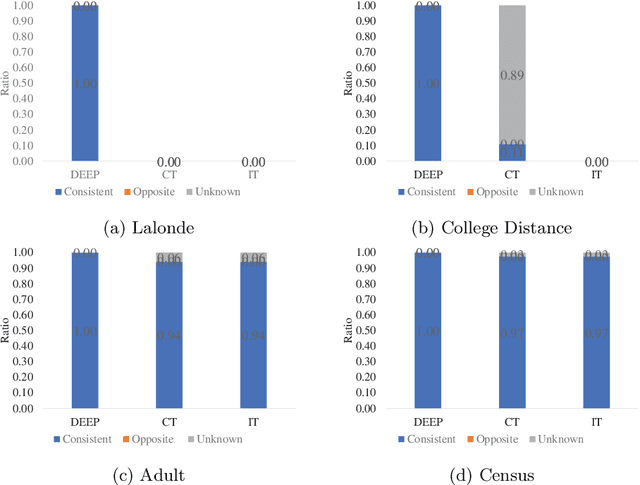
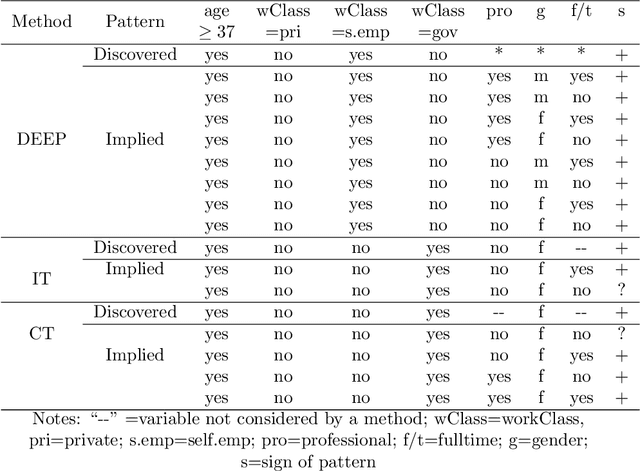
In personalised decision making, evidence is required to determine suitable actions for individuals. Such evidence can be obtained by identifying treatment effect heterogeneity in different subgroups of the population. In this paper, we design a new type of pattern, treatment effect pattern to represent and discover treatment effect heterogeneity from data for determining whether a treatment will work for an individual or not. Our purpose is to use the computational power to find the most specific and relevant conditions for individuals with respect to a treatment or an action to assist with personalised decision making. Most existing work on identifying treatment effect heterogeneity takes a top-down or partitioning based approach to search for subgroups with heterogeneous treatment effects. We propose a bottom-up generalisation algorithm to obtain the most specific patterns that fit individual circumstances the best for personalised decision making. For the generalisation, we follow a consistency driven strategy to maintain inner-group homogeneity and inter-group heterogeneity of treatment effects. We also employ graphical causal modelling technique to identify adjustment variables for reliable treatment effect pattern discovery. Our method can find the treatment effect patterns reliably as validated by the experiments. The method is faster than the two existing machine learning methods for heterogeneous treatment effect identification and it produces subgroups with higher inner-group treatment effect homogeneity.