 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentify treatment effect patterns for personalised decisions
Jun 14, 2019
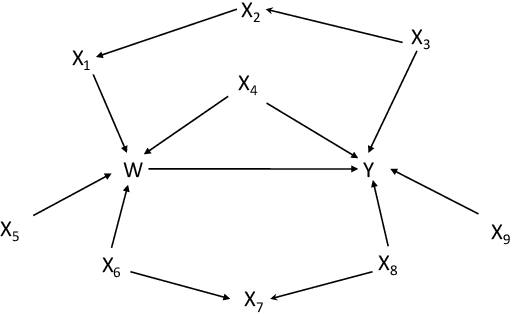
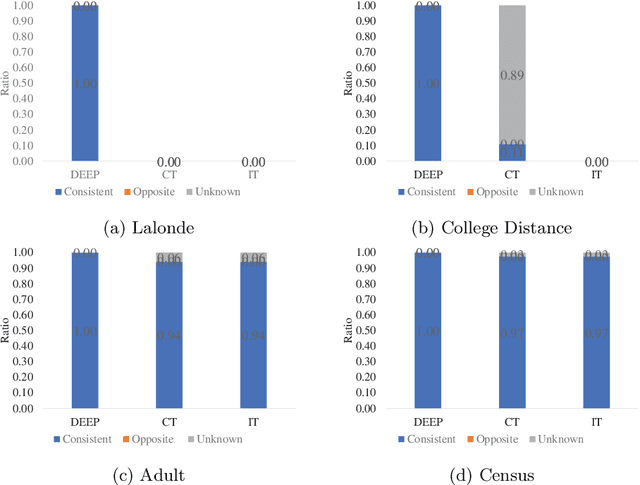
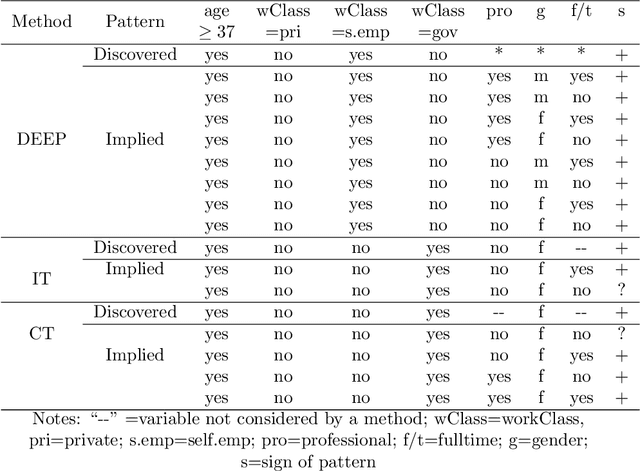
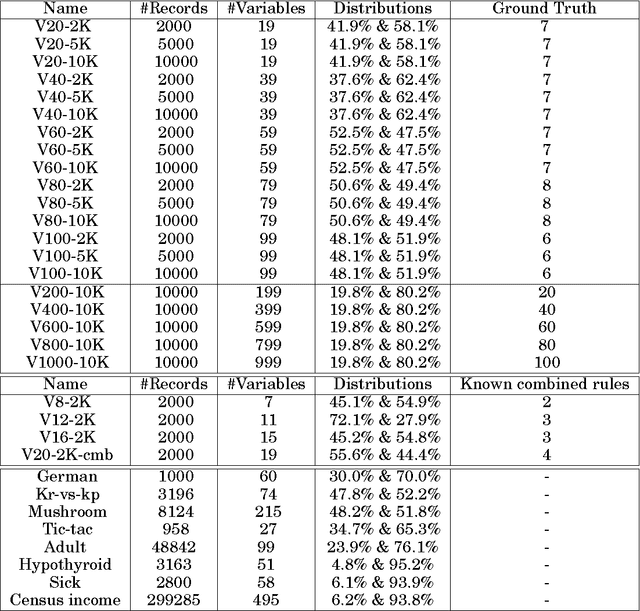
In personalised decision making, evidence is required to determine suitable actions for individuals. Such evidence can be obtained by identifying treatment effect heterogeneity in different subgroups of the population. In this paper, we design a new type of pattern, treatment effect pattern to represent and discover treatment effect heterogeneity from data for determining whether a treatment will work for an individual or not. Our purpose is to use the computational power to find the most specific and relevant conditions for individuals with respect to a treatment or an action to assist with personalised decision making. Most existing work on identifying treatment effect heterogeneity takes a top-down or partitioning based approach to search for subgroups with heterogeneous treatment effects. We propose a bottom-up generalisation algorithm to obtain the most specific patterns that fit individual circumstances the best for personalised decision making. For the generalisation, we follow a consistency driven strategy to maintain inner-group homogeneity and inter-group heterogeneity of treatment effects. We also employ graphical causal modelling technique to identify adjustment variables for reliable treatment effect pattern discovery. Our method can find the treatment effect patterns reliably as validated by the experiments. The method is faster than the two existing machine learning methods for heterogeneous treatment effect identification and it produces subgroups with higher inner-group treatment effect homogeneity.
Discovering Context Specific Causal Relationships
Aug 20, 2018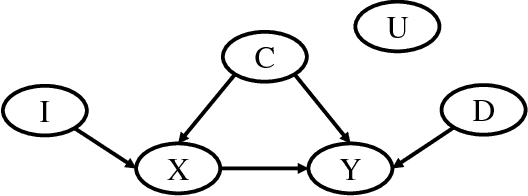

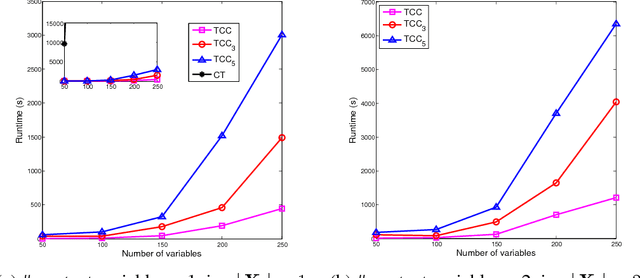
With the increasing need of personalised decision making, such as personalised medicine and online recommendations, a growing attention has been paid to the discovery of the context and heterogeneity of causal relationships. Most existing methods, however, assume a known cause (e.g. a new drug) and focus on identifying from data the contexts of heterogeneous effects of the cause (e.g. patient groups with different responses to the new drug). There is no approach to efficiently detecting directly from observational data context specific causal relationships, i.e. discovering the causes and their contexts simultaneously. In this paper, by taking the advantages of highly efficient decision tree induction and the well established causal inference framework, we propose the Tree based Context Causal rule discovery (TCC) method, for efficient exploration of context specific causal relationships from data. Experiments with both synthetic and real world data sets show that TCC can effectively discover context specific causal rules from the data.
* This paper has been accepted by Intelligent Data Analysis
Mining Combined Causes in Large Data Sets
Oct 15, 2015
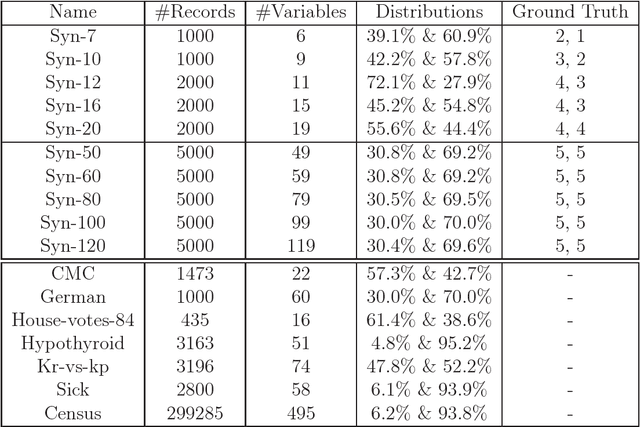
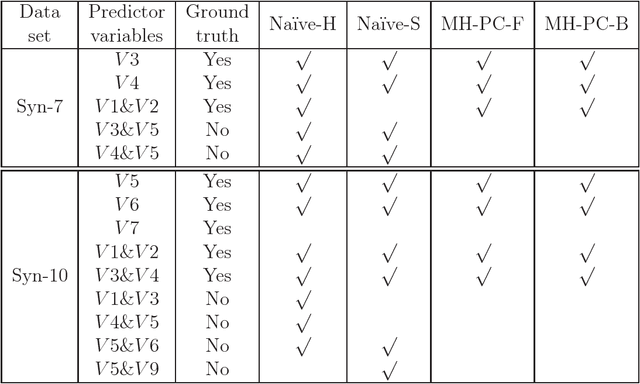
In recent years, many methods have been developed for detecting causal relationships in observational data. Some of them have the potential to tackle large data sets. However, these methods fail to discover a combined cause, i.e. a multi-factor cause consisting of two or more component variables which individually are not causes. A straightforward approach to uncovering a combined cause is to include both individual and combined variables in the causal discovery using existing methods, but this scheme is computationally infeasible due to the huge number of combined variables. In this paper, we propose a novel approach to address this practical causal discovery problem, i.e. mining combined causes in large data sets. The experiments with both synthetic and real world data sets show that the proposed method can obtain high-quality causal discoveries with a high computational efficiency.
From Observational Studies to Causal Rule Mining
Aug 16, 2015
Randomised controlled trials (RCTs) are the most effective approach to causal discovery, but in many circumstances it is impossible to conduct RCTs. Therefore observational studies based on passively observed data are widely accepted as an alternative to RCTs. However, in observational studies, prior knowledge is required to generate the hypotheses about the cause-effect relationships to be tested, hence they can only be applied to problems with available domain knowledge and a handful of variables. In practice, many data sets are of high dimensionality, which leaves observational studies out of the opportunities for causal discovery from such a wealth of data sources. In another direction, many efficient data mining methods have been developed to identify associations among variables in large data sets. The problem is, causal relationships imply associations, but the reverse is not always true. However we can see the synergy between the two paradigms here. Specifically, association rule mining can be used to deal with the high-dimensionality problem while observational studies can be utilised to eliminate non-causal associations. In this paper we propose the concept of causal rules (CRs) and develop an algorithm for mining CRs in large data sets. We use the idea of retrospective cohort studies to detect CRs based on the results of association rule mining. Experiments with both synthetic and real world data sets have demonstrated the effectiveness and efficiency of CR mining. In comparison with the commonly used causal discovery methods, the proposed approach in general is faster and has better or competitive performance in finding correct or sensible causes. It is also capable of finding a cause consisting of multiple variables, a feature that other causal discovery methods do not possess.
* This paper has been accepted by ACM TIST journal and will be available soon
Causal Decision Trees
Aug 16, 2015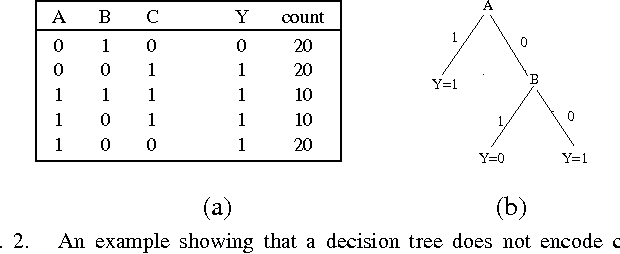
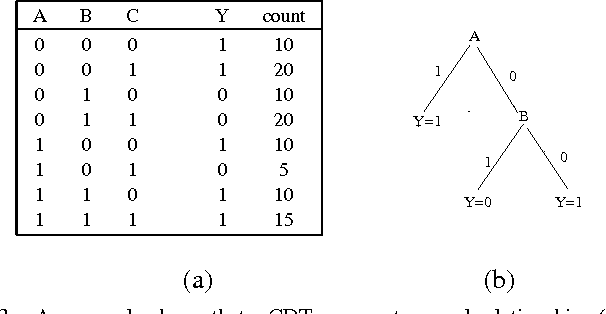
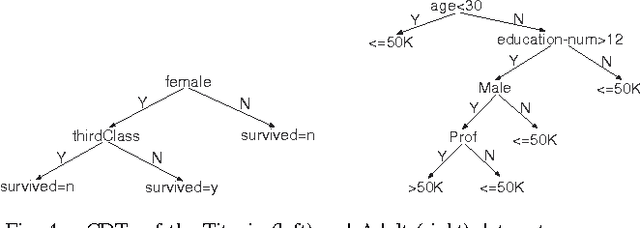
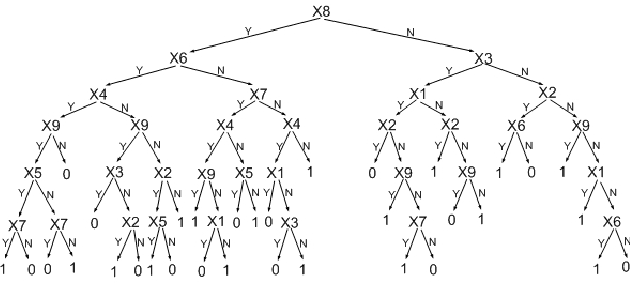
Uncovering causal relationships in data is a major objective of data analytics. Causal relationships are normally discovered with designed experiments, e.g. randomised controlled trials, which, however are expensive or infeasible to be conducted in many cases. Causal relationships can also be found using some well designed observational studies, but they require domain experts' knowledge and the process is normally time consuming. Hence there is a need for scalable and automated methods for causal relationship exploration in data. Classification methods are fast and they could be practical substitutes for finding causal signals in data. However, classification methods are not designed for causal discovery and a classification method may find false causal signals and miss the true ones. In this paper, we develop a causal decision tree where nodes have causal interpretations. Our method follows a well established causal inference framework and makes use of a classic statistical test. The method is practical for finding causal signals in large data sets.