 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALPBench: A Benchmark for Attribution-level Long-term Personal Behavior Understanding
Feb 03, 2026Recent advances in large language models have highlighted their potential for personalized recommendation, where accurately capturing user preferences remains a key challenge. Leveraging their strong reasoning and generalization capabilities, LLMs offer new opportunities for modeling long-term user behavior. To systematically evaluate this, we introduce ALPBench, a Benchmark for Attribution-level Long-term Personal Behavior Understanding. Unlike item-focused benchmarks, ALPBench predicts user-interested attribute combinations, enabling ground-truth evaluation even for newly introduced items. It models preferences from long-term historical behaviors rather than users' explicitly expressed requests, better reflecting enduring interests. User histories are represented as natural language sequences, allowing interpretable, reasoning-based personalization. ALPBench enables fine-grained evaluation of personalization by focusing on the prediction of attribute combinations task that remains highly challenging for current LLMs due to the need to capture complex interactions among multiple attributes and reason over long-term user behavior sequences.
Few-Shot Adversarial Prompt Learning on Vision-Language Models
Mar 21, 2024The vulnerability of deep neural networks to imperceptible adversarial perturbations has attracted widespread attention. Inspired by the success of vision-language foundation models, previous efforts achieved zero-shot adversarial robustness by aligning adversarial visual features with text supervision. However, in practice, they are still unsatisfactory due to several issues, including heavy adaptation cost, suboptimal text supervision, and uncontrolled natural generalization capacity. In this paper, to address these issues, we propose a few-shot adversarial prompt framework where adapting input sequences with limited data makes significant adversarial robustness improvement. Specifically, we achieve this by providing adversarially correlated text supervision that is end-to-end learned from adversarial examples. We also propose a novel training objective that enhances the consistency of multi-modal features while encourages differentiated uni-modal features between natural and adversarial examples. The proposed framework gives access to learn adversarial text supervision, which provides superior cross-modal adversarial alignment and matches state-of-the-art zero-shot adversarial robustness with only 1% training data.
Entity Linking in Tabular Data Needs the Right Attention
Jul 05, 2022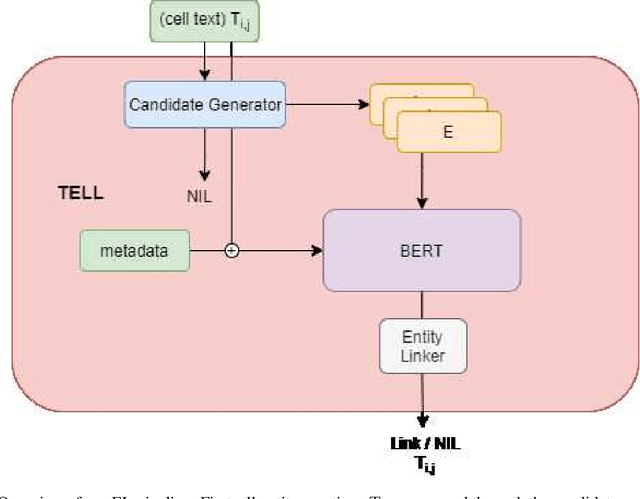
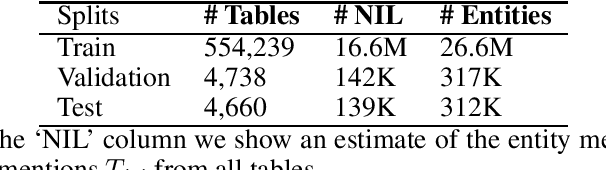
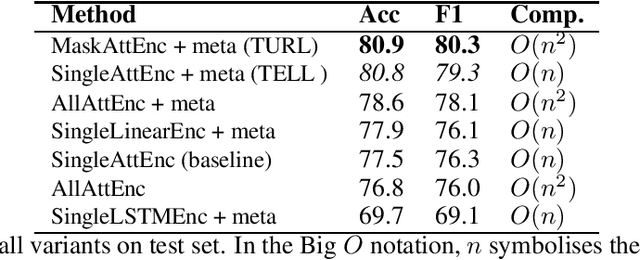
Understanding the semantic meaning of tabular data requires Entity Linking (EL), in order to associate each cell value to a real-world entity in a Knowledge Base (KB). In this work, we focus on end-to-end solutions for EL on tabular data that do not rely on fact lookup in the target KB. Tabular data contains heterogeneous and sparse context, including column headers, cell values and table captions. We experiment with various models to generate a vector representation for each cell value to be linked. Our results show that it is critical to apply an attention mechanism as well as an attention mask, so that the model can only attend to the most relevant context and avoid information dilution. The most relevant context includes: same-row cells, same-column cells, headers and caption. Computational complexity, however, grows quadratically with the size of tabular data for such a complex model. We achieve constant memory usage by introducing a Tabular Entity Linking Lite model (TELL ) that generates vector representation for a cell based only on its value, the table headers and the table caption. TELL achieves 80.8% accuracy on Wikipedia tables, which is only 0.1% lower than the state-of-the-art model with quadratic memory usage.
Generating Semantically Valid Adversarial Questions for TableQA
May 26, 2020



Adversarial attack on question answering systems over tabular data (TableQA) can help evaluate to what extent they can understand natural language questions and reason with tables. However, generating natural language adversarial questions is difficult, because even a single character swap could lead to huge semantic difference in human perception. In this paper, we propose SAGE (Semantically valid Adversarial GEnerator), a Wasserstein sequence-to-sequence model for TableQA white-box attack. To preserve meaning of original questions, we apply minimum risk training with SIMILE and entity delexicalization. We use Gumbel-Softmax to incorporate adversarial loss for end-to-end training. Our experiments show that SAGE outperforms existing local attack models on semantic validity and fluency while achieving a good attack success rate. Finally, we demonstrate that adversarial training with SAGE augmented data can improve performance and robustness of TableQA systems.
Clickbait Detection in Tweets Using Self-attentive Network
Oct 15, 2017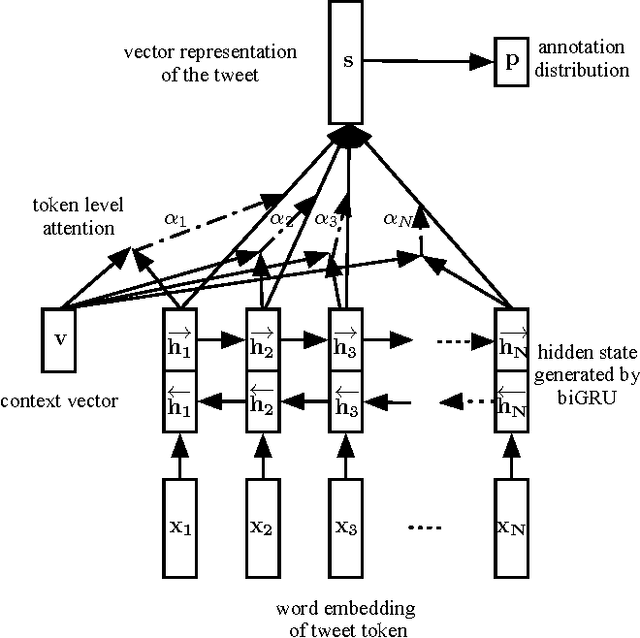
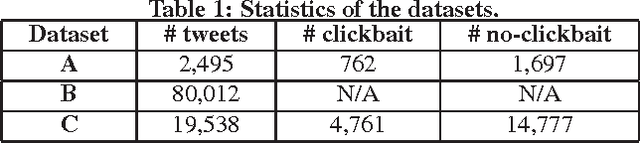
Clickbait detection in tweets remains an elusive challenge. In this paper, we describe the solution for the Zingel Clickbait Detector at the Clickbait Challenge 2017, which is capable of evaluating each tweet's level of click baiting. We first reformat the regression problem as a multi-classification problem, based on the annotation scheme. To perform multi-classification, we apply a token-level, self-attentive mechanism on the hidden states of bi-directional Gated Recurrent Units (biGRU), which enables the model to generate tweets' task-specific vector representations by attending to important tokens. The self-attentive neural network can be trained end-to-end, without involving any manual feature engineering. Our detector ranked first in the final evaluation of Clickbait Challenge 2017.