 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Knowledge Concept Annotation and Question Representation Learning for Knowledge Tracing
Oct 02, 2024



Knowledge tracing (KT) is a popular approach for modeling students' learning progress over time, which can enable more personalized and adaptive learning. However, existing KT approaches face two major limitations: (1) they rely heavily on expert-defined knowledge concepts (KCs) in questions, which is time-consuming and prone to errors; and (2) KT methods tend to overlook the semantics of both questions and the given KCs. In this work, we address these challenges and present KCQRL, a framework for automated knowledge concept annotation and question representation learning that can improve the effectiveness of any existing KT model. First, we propose an automated KC annotation process using large language models (LLMs), which generates question solutions and then annotates KCs in each solution step of the questions. Second, we introduce a contrastive learning approach to generate semantically rich embeddings for questions and solution steps, aligning them with their associated KCs via a tailored false negative elimination approach. These embeddings can be readily integrated into existing KT models, replacing their randomly initialized embeddings. We demonstrate the effectiveness of KCQRL across 15 KT algorithms on two large real-world Math learning datasets, where we achieve consistent performance improvements.
In-Context Few-Shot Relation Extraction via Pre-Trained Language Models
Oct 17, 2023Relation extraction aims at inferring structured human knowledge from textual documents. State-of-the-art methods based on language models commonly have two limitations: (1) they require named entities to be either given as input or infer them, which introduces additional noise, and (2) they require human annotations of documents. As a remedy, we present a novel framework for in-context few-shot relation extraction via pre-trained language models. To the best of our knowledge, we are the first to reformulate the relation extraction task as a tailored in-context few-shot learning paradigm. Thereby, we achieve crucial benefits in that we eliminate the need for both named entity recognition and human annotation of documents. Unlike existing methods based on fine-tuning, our framework is flexible in that it can be easily updated for a new set of relations without re-training. We evaluate our framework using DocRED, the largest publicly available dataset for document-level relation extraction, and demonstrate that our framework achieves state-of-the-art performance. Finally, our framework allows us to identify missing annotations, and we thus show that our framework actually performs much better than the original labels from the development set of DocRED.
Behavioral graph fraud detection in E-commerce
Oct 13, 2022

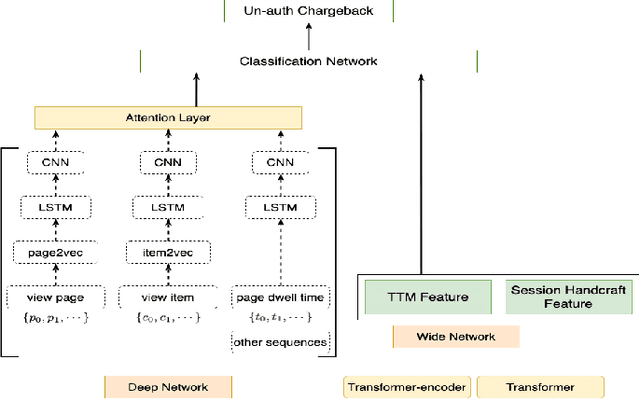
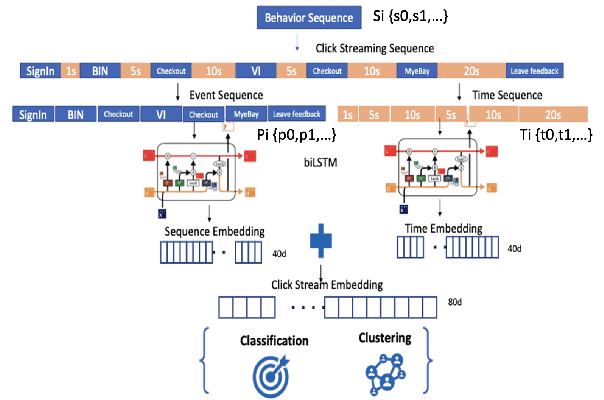
In e-commerce industry, graph neural network methods are the new trends for transaction risk modeling.The power of graph algorithms lie in the capability to catch transaction linking network information, which is very hard to be captured by other algorithms.However, in most existing approaches, transaction or user connections are defined by hard link strategies on shared properties, such as same credit card, same device, same ip address, same shipping address, etc. Those types of strategies will result in sparse linkages by entities with strong identification characteristics (ie. device) and over-linkages by entities that could be widely shared (ie. ip address), making it more difficult to learn useful information from graph. To address aforementioned problems, we present a novel behavioral biometric based method to establish transaction linkings based on user behavioral similarities, then train an unsupervised GNN to extract embedding features for downstream fraud prediction tasks. To our knowledge, this is the first time similarity based soft link has been used in graph embedding applications. To speed up similarity calculation, we apply an in-house GPU based HDBSCAN clustering method to remove highly concentrated and isolated nodes before graph construction. Our experiments show that embedding features learned from similarity based behavioral graph have achieved significant performance increase to the baseline fraud detection model in various business scenarios. In new guest buyer transaction scenario, this segment is a challenge for traditional method, we can make precision increase from 0.82 to 0.86 at the same recall of 0.27, which means we can decrease false positive rate using this method.
Contrastive Learning for Unsupervised Domain Adaptation of Time Series
Jun 13, 2022



Unsupervised domain adaptation (UDA) aims at learning a machine learning model using a labeled source domain that performs well on a similar yet different, unlabeled target domain. UDA is important in many applications such as medicine, where it is used to adapt risk scores across different patient cohorts. In this paper, we develop a novel framework for UDA of time series data, called CLUDA. Specifically, we propose a contrastive learning framework to learn domain-invariant semantics in multivariate time series, so that these preserve label information for the prediction task. In our framework, we further capture semantic variation between source and target domain via nearest-neighbor contrastive learning. To the best of our knowledge, ours is the first framework to learn domain-invariant semantic information for UDA of time series data. We evaluate our framework using large-scale, real-world datasets with medical time series (i.e., MIMIC-IV and AmsterdamUMCdb) to demonstrate its effectiveness and show that it achieves state-of-the-art performance for time series UDA.