 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation for Point Cloud Semantic Segmentation via Graph Matching
Aug 09, 2022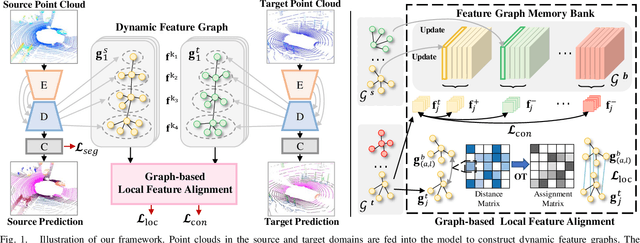


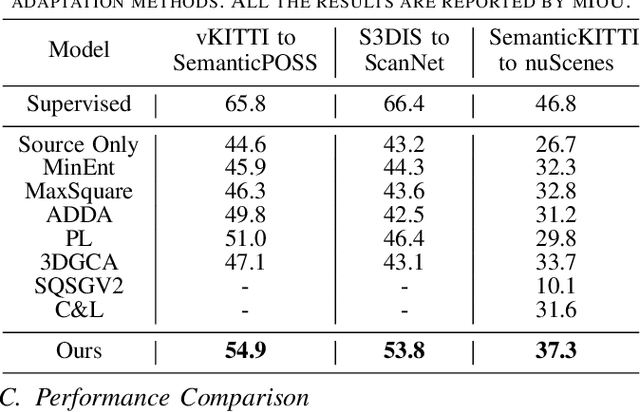
Unsupervised domain adaptation for point cloud semantic segmentation has attracted great attention due to its effectiveness in learning with unlabeled data. Most of existing methods use global-level feature alignment to transfer the knowledge from the source domain to the target domain, which may cause the semantic ambiguity of the feature space. In this paper, we propose a graph-based framework to explore the local-level feature alignment between the two domains, which can reserve semantic discrimination during adaptation. Specifically, in order to extract local-level features, we first dynamically construct local feature graphs on both domains and build a memory bank with the graphs from the source domain. In particular, we use optimal transport to generate the graph matching pairs. Then, based on the assignment matrix, we can align the feature distributions between the two domains with the graph-based local feature loss. Furthermore, we consider the correlation between the features of different categories and formulate a category-guided contrastive loss to guide the segmentation model to learn discriminative features on the target domain. Extensive experiments on different synthetic-to-real and real-to-real domain adaptation scenarios demonstrate that our method can achieve state-of-the-art performance.
RA-Depth: Resolution Adaptive Self-Supervised Monocular Depth Estimation
Jul 26, 2022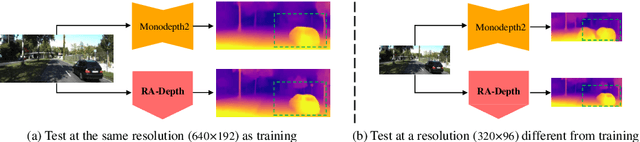

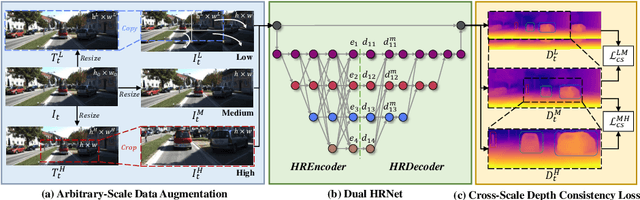
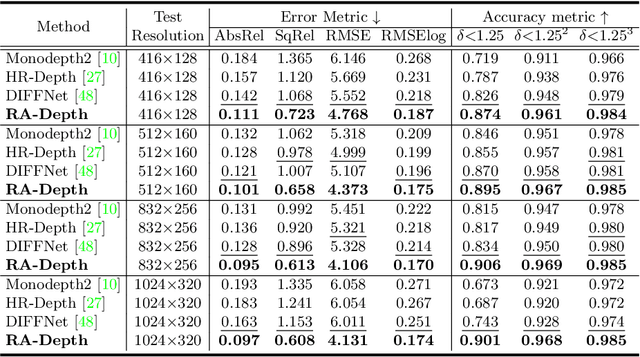
Existing self-supervised monocular depth estimation methods can get rid of expensive annotations and achieve promising results. However, these methods suffer from severe performance degradation when directly adopting a model trained on a fixed resolution to evaluate at other different resolutions. In this paper, we propose a resolution adaptive self-supervised monocular depth estimation method (RA-Depth) by learning the scale invariance of the scene depth. Specifically, we propose a simple yet efficient data augmentation method to generate images with arbitrary scales for the same scene. Then, we develop a dual high-resolution network that uses the multi-path encoder and decoder with dense interactions to aggregate multi-scale features for accurate depth inference. Finally, to explicitly learn the scale invariance of the scene depth, we formulate a cross-scale depth consistency loss on depth predictions with different scales. Extensive experiments on the KITTI, Make3D and NYU-V2 datasets demonstrate that RA-Depth not only achieves state-of-the-art performance, but also exhibits a good ability of resolution adaptation.