 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Morph-Patch Transformer for Aortic Vessel Segmentation
Nov 11, 2025Accurate segmentation of aortic vascular structures is critical for diagnosing and treating cardiovascular diseases.Traditional Transformer-based models have shown promise in this domain by capturing long-range dependencies between vascular features. However, their reliance on fixed-size rectangular patches often influences the integrity of complex vascular structures, leading to suboptimal segmentation accuracy. To address this challenge, we propose the adaptive Morph Patch Transformer (MPT), a novel architecture specifically designed for aortic vascular segmentation. Specifically, MPT introduces an adaptive patch partitioning strategy that dynamically generates morphology-aware patches aligned with complex vascular structures. This strategy can preserve semantic integrity of complex vascular structures within individual patches. Moreover, a Semantic Clustering Attention (SCA) method is proposed to dynamically aggregate features from various patches with similar semantic characteristics. This method enhances the model's capability to segment vessels of varying sizes, preserving the integrity of vascular structures. Extensive experiments on three open-source dataset(AVT, AortaSeg24 and TBAD) demonstrate that MPT achieves state-of-the-art performance, with improvements in segmenting intricate vascular structures.
Momentum-GS: Momentum Gaussian Self-Distillation for High-Quality Large Scene Reconstruction
Dec 06, 2024



3D Gaussian Splatting has demonstrated notable success in large-scale scene reconstruction, but challenges persist due to high training memory consumption and storage overhead. Hybrid representations that integrate implicit and explicit features offer a way to mitigate these limitations. However, when applied in parallelized block-wise training, two critical issues arise since reconstruction accuracy deteriorates due to reduced data diversity when training each block independently, and parallel training restricts the number of divided blocks to the available number of GPUs. To address these issues, we propose Momentum-GS, a novel approach that leverages momentum-based self-distillation to promote consistency and accuracy across the blocks while decoupling the number of blocks from the physical GPU count. Our method maintains a teacher Gaussian decoder updated with momentum, ensuring a stable reference during training. This teacher provides each block with global guidance in a self-distillation manner, promoting spatial consistency in reconstruction. To further ensure consistency across the blocks, we incorporate block weighting, dynamically adjusting each block's weight according to its reconstruction accuracy. Extensive experiments on large-scale scenes show that our method consistently outperforms existing techniques, achieving a 12.8% improvement in LPIPS over CityGaussian with much fewer divided blocks and establishing a new state of the art. Project page: https://jixuan-fan.github.io/Momentum-GS_Page/
Self-Calibrated CLIP for Training-Free Open-Vocabulary Segmentation
Nov 24, 2024
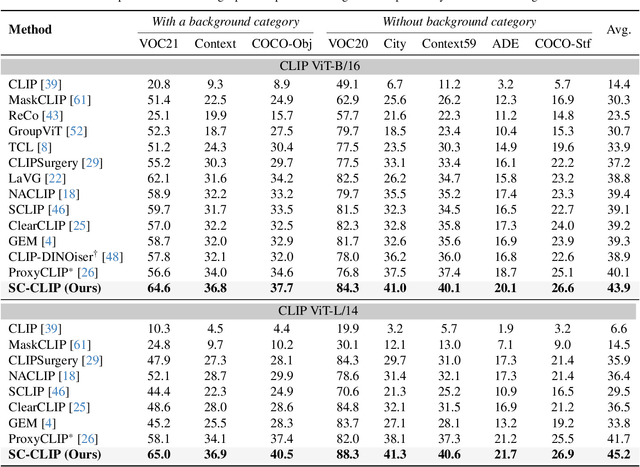
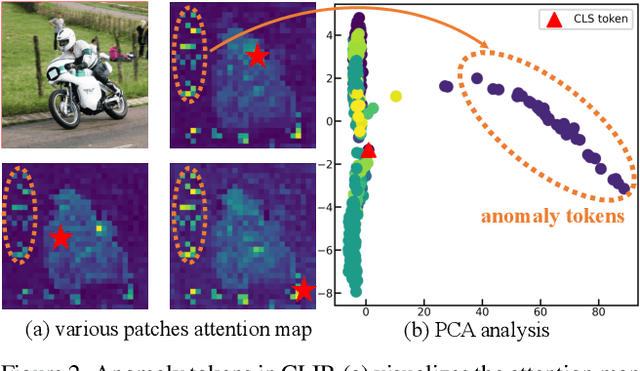
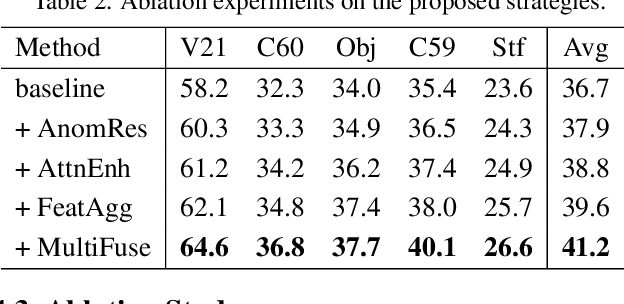
Recent advancements in pre-trained vision-language models like CLIP, have enabled the task of open-vocabulary segmentation. CLIP demonstrates impressive zero-shot capabilities in various downstream tasks that require holistic image understanding. However, due to its image-level pre-training, CLIP struggles to capture local details, resulting in poor performance in segmentation tasks. Our analysis reveals that anomaly tokens emerge during the forward pass, drawing excessive attention from normal patch tokens, thereby diminishing spatial awareness. To address this issue, we propose Self-Calibrated CLIP (SC-CLIP), a training-free method that calibrates CLIP to produce finer-grained representations while preserving its original generalization ability, without introducing new parameters or relying on additional backbones. Specifically, we first identify and resolve the anomaly tokens to mitigate their negative impact. Next, we enhance feature discriminability and attention correlation by leveraging the semantic consistency found in CLIP's intermediate features. Furthermore, we employ multi-level feature fusion to enrich details. Collectively, these strategies enhance CLIP's feature representation with greater granularity and coherence. Experimental results demonstrate the effectiveness of SC-CLIP, achieving state-of-the-art results across eight semantic segmentation datasets and surpassing previous methods by 9.5%. Notably, SC-CLIP boosts the performance of vanilla CLIP ViT-L/14 by 6.8 times. Our source code is available at https://github.com/SuleBai/SC-CLIP.