 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparDL: Distributed Deep Learning Training with Efficient Sparse Communication
Apr 03, 2023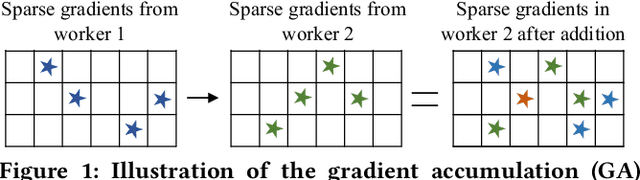

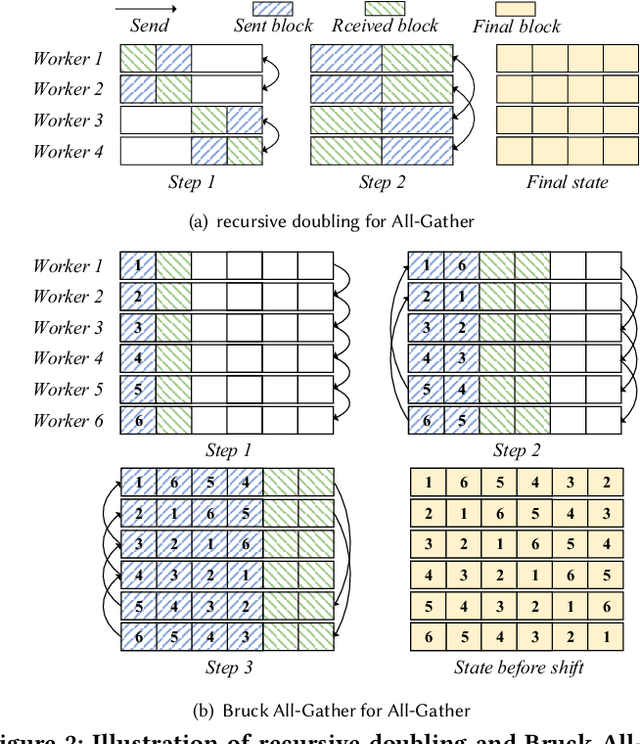
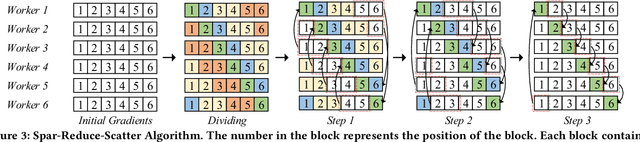
Top-$k$ sparsification has recently been widely used to reduce the communication volume in distributed deep learning; however, due to Gradient Accumulation (GA) dilemma, the performance of top-$k$ sparsification is still limited. Several methods have been proposed to handle the GA dilemma but have two drawbacks: (1) they are frustrated by the high communication complexity as they introduce a large amount of extra transmission; (2) they are not flexible for non-power-of-two numbers of workers. To solve these two problems, we propose a flexible and efficient sparse communication framework, dubbed SparDL. SparDL uses the Spar-Reduce-Scatter algorithm to solve the GA dilemma without additional communication operations and is flexible to any number of workers. Besides, to further reduce the communication complexity and adjust the proportion of latency and bandwidth cost in communication complexity, we propose the Spar-All-Gather algorithm as part of SparDL. Extensive experiments validate the superiority of SparDL.