 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Guided Network for Salient Object Detection in Optical Remote Sensing Images
Jul 05, 2022

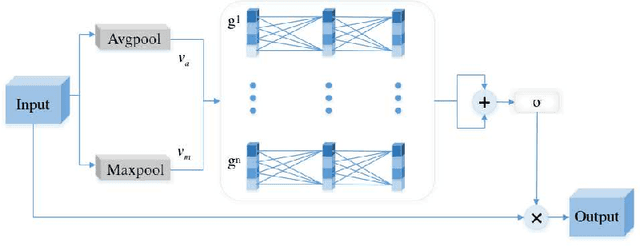

Due to the extreme complexity of scale and shape as well as the uncertainty of the predicted location, salient object detection in optical remote sensing images (RSI-SOD) is a very difficult task. The existing SOD methods can satisfy the detection performance for natural scene images, but they are not well adapted to RSI-SOD due to the above-mentioned image characteristics in remote sensing images. In this paper, we propose a novel Attention Guided Network (AGNet) for SOD in optical RSIs, including position enhancement stage and detail refinement stage. Specifically, the position enhancement stage consists of a semantic attention module and a contextual attention module to accurately describe the approximate location of salient objects. The detail refinement stage uses the proposed self-refinement module to progressively refine the predicted results under the guidance of attention and reverse attention. In addition, the hybrid loss is applied to supervise the training of the network, which can improve the performance of the model from three perspectives of pixel, region and statistics. Extensive experiments on two popular benchmarks demonstrate that AGNet achieves competitive performance compared to other state-of-the-art methods. The code will be available at https://github.com/NuaaYH/AGNet.
A lightweight multi-scale context network for salient object detection in optical remote sensing images
May 18, 2022

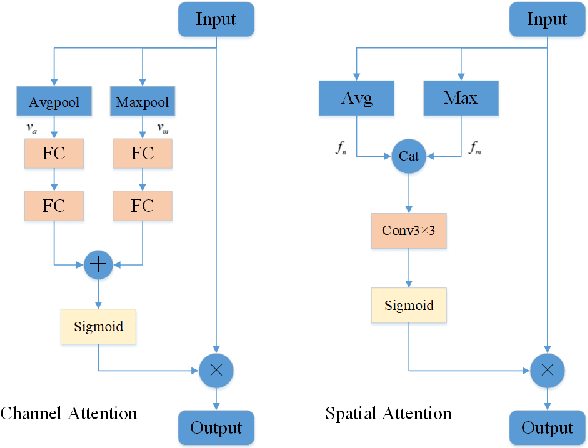

Due to the more dramatic multi-scale variations and more complicated foregrounds and backgrounds in optical remote sensing images (RSIs), the salient object detection (SOD) for optical RSIs becomes a huge challenge. However, different from natural scene images (NSIs), the discussion on the optical RSI SOD task still remains scarce. In this paper, we propose a multi-scale context network, namely MSCNet, for SOD in optical RSIs. Specifically, a multi-scale context extraction module is adopted to address the scale variation of salient objects by effectively learning multi-scale contextual information. Meanwhile, in order to accurately detect complete salient objects in complex backgrounds, we design an attention-based pyramid feature aggregation mechanism for gradually aggregating and refining the salient regions from the multi-scale context extraction module. Extensive experiments on two benchmarks demonstrate that MSCNet achieves competitive performance with only 3.26M parameters. The code will be available at https://github.com/NuaaYH/MSCNet.
Multi-scale Edge-based U-shape Network for Salient Object Detection
Aug 21, 2021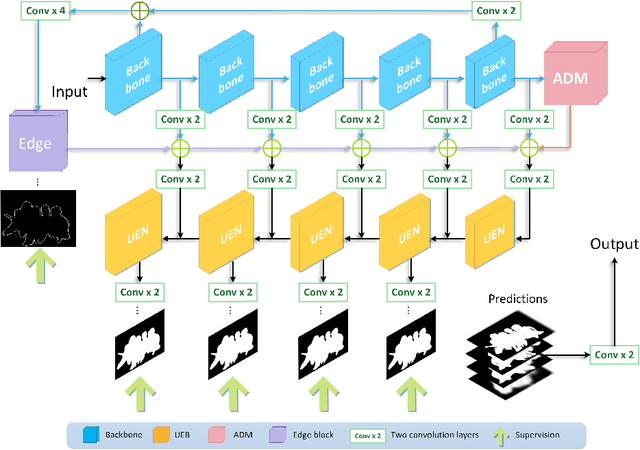



Deep-learning based salient object detection methods achieve great improvements. However, there are still problems existing in the predictions, such as blurry boundary and inaccurate location, which is mainly caused by inadequate feature extraction and integration. In this paper, we propose a Multi-scale Edge-based U-shape Network (MEUN) to integrate various features at different scales to achieve better performance. To extract more useful information for boundary prediction, U-shape Edge Network modules are embedded in each decoder units. Besides, the additional down-sampling module alleviates the location inaccuracy. Experimental results on four benchmark datasets demonstrate the validity and reliability of the proposed method. Multi-scale Edge based U-shape Network also shows its superiority when compared with 15 state-of-the-art salient object detection methods.