 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Using Regression Models to Build Defect Classifiers
Feb 12, 2022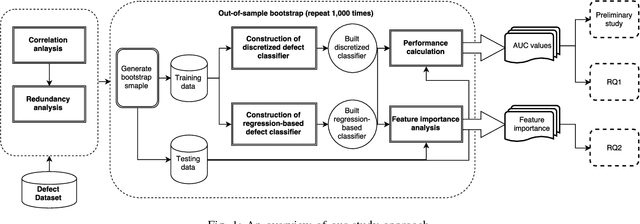
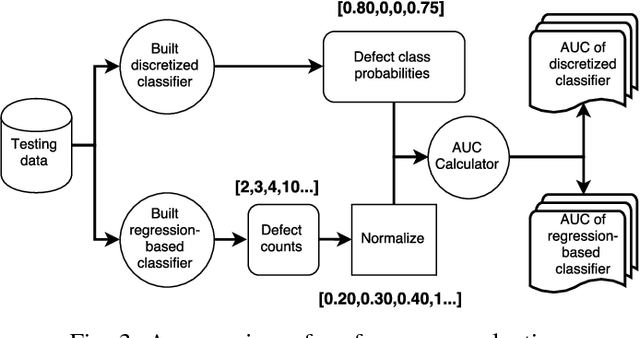
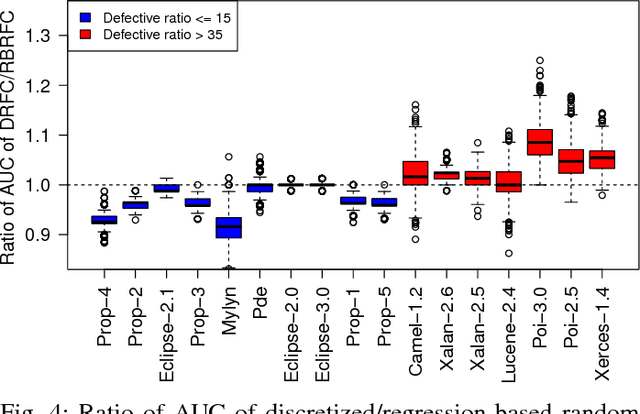
It is common practice to discretize continuous defect counts into defective and non-defective classes and use them as a target variable when building defect classifiers (discretized classifiers). However, this discretization of continuous defect counts leads to information loss that might affect the performance and interpretation of defect classifiers. Another possible approach to build defect classifiers is through the use of regression models then discretizing the predicted defect counts into defective and non-defective classes (regression-based classifiers). In this paper, we compare the performance and interpretation of defect classifiers that are built using both approaches (i.e., discretized classifiers and regression-based classifiers) across six commonly used machine learning classifiers (i.e., linear/logistic regression, random forest, KNN, SVM, CART, and neural networks) and 17 datasets. We find that: i) Random forest based classifiers outperform other classifiers (best AUC) for both classifier building approaches; ii) In contrast to common practice, building a defect classifier using discretized defect counts (i.e., discretized classifiers) does not always lead to better performance. Hence we suggest that future defect classification studies should consider building regression-based classifiers (in particular when the defective ratio of the modeled dataset is low). Moreover, we suggest that both approaches for building defect classifiers should be explored, so the best-performing classifier can be used when determining the most influential features.
Impact of Discretization Noise of the Dependent variable on Machine Learning Classifiers in Software Engineering
Feb 12, 2022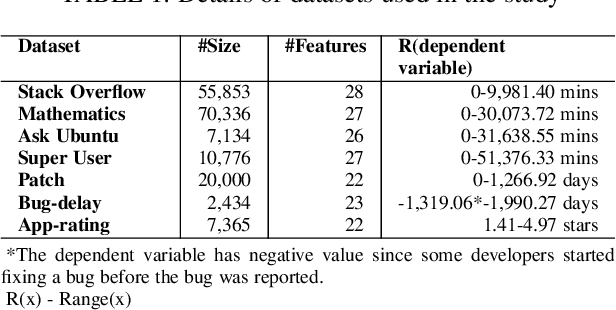
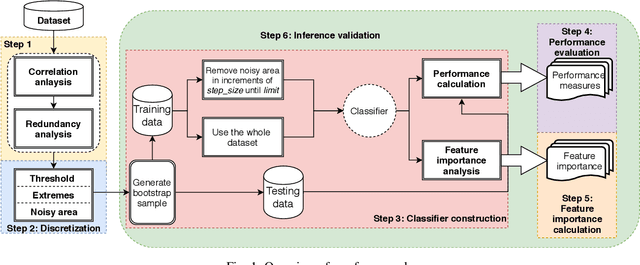
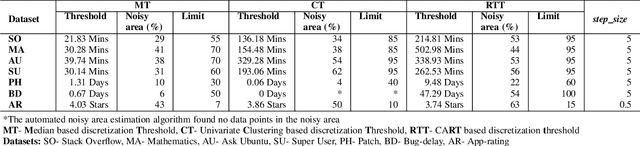
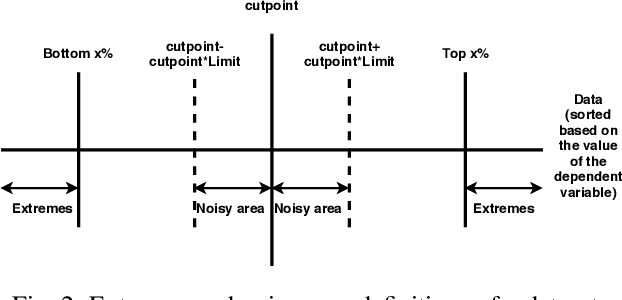
Researchers usually discretize a continuous dependent variable into two target classes by introducing an artificial discretization threshold (e.g., median). However, such discretization may introduce noise (i.e., discretization noise) due to ambiguous class loyalty of data points that are close to the artificial threshold. Previous studies do not provide a clear directive on the impact of discretization noise on the classifiers and how to handle such noise. In this paper, we propose a framework to help researchers and practitioners systematically estimate the impact of discretization noise on classifiers in terms of its impact on various performance measures and the interpretation of classifiers. Through a case study of 7 software engineering datasets, we find that: 1) discretization noise affects the different performance measures of a classifier differently for different datasets; 2) Though the interpretation of the classifiers are impacted by the discretization noise on the whole, the top 3 most important features are not affected by the discretization noise. Therefore, we suggest that practitioners and researchers use our framework to understand the impact of discretization noise on the performance of their built classifiers and estimate the exact amount of discretization noise to be discarded from the dataset to avoid the negative impact of such noise.
The impact of feature importance methods on the interpretation of defect classifiers
Feb 04, 2022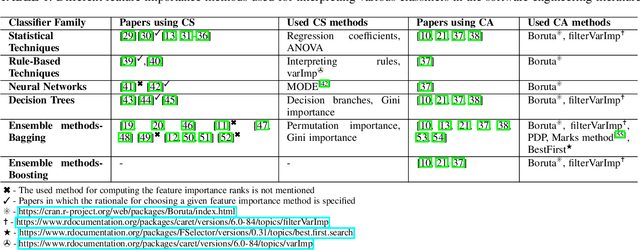



Classifier specific (CS) and classifier agnostic (CA) feature importance methods are widely used (often interchangeably) by prior studies to derive feature importance ranks from a defect classifier. However, different feature importance methods are likely to compute different feature importance ranks even for the same dataset and classifier. Hence such interchangeable use of feature importance methods can lead to conclusion instabilities unless there is a strong agreement among different methods. Therefore, in this paper, we evaluate the agreement between the feature importance ranks associated with the studied classifiers through a case study of 18 software projects and six commonly used classifiers. We find that: 1) The computed feature importance ranks by CA and CS methods do not always strongly agree with each other. 2) The computed feature importance ranks by the studied CA methods exhibit a strong agreement including the features reported at top-1 and top-3 ranks for a given dataset and classifier, while even the commonly used CS methods yield vastly different feature importance ranks. Such findings raise concerns about the stability of conclusions across replicated studies. We further observe that the commonly used defect datasets are rife with feature interactions and these feature interactions impact the computed feature importance ranks of the CS methods (not the CA methods). We demonstrate that removing these feature interactions, even with simple methods like CFS improves agreement between the computed feature importance ranks of CA and CS methods. In light of our findings, we provide guidelines for stakeholders and practitioners when performing model interpretation and directions for future research, e.g., future research is needed to investigate the impact of advanced feature interaction removal methods on computed feature importance ranks of different CS methods.
Towards effective AI-powered agile project management
Dec 27, 2018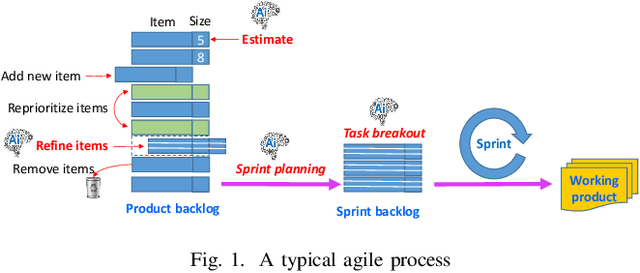
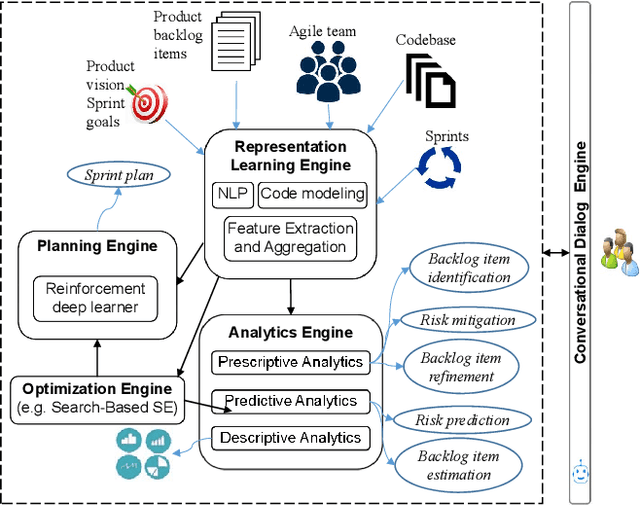
The rise of Artificial intelligence (AI) has the potential to significantly transform the practice of project management. Project management has a large socio-technical element with many uncertainties arising from variability in human aspects e.g., customers' needs, developers' performance and team dynamics. AI can assist project managers and team members by automating repetitive, high-volume tasks to enable project analytics for estimation and risk prediction, providing actionable recommendations, and even making decisions. AI is potentially a game changer for project management in helping to accelerate productivity and increase project success rates. In this paper, we propose a framework where AI technologies can be leveraged to offer support for managing agile projects, which have become increasingly popular in the industry.