 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe impact of feature importance methods on the interpretation of defect classifiers
Paper and Code
Feb 04, 2022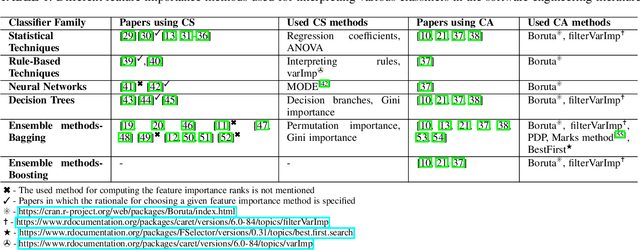



Classifier specific (CS) and classifier agnostic (CA) feature importance methods are widely used (often interchangeably) by prior studies to derive feature importance ranks from a defect classifier. However, different feature importance methods are likely to compute different feature importance ranks even for the same dataset and classifier. Hence such interchangeable use of feature importance methods can lead to conclusion instabilities unless there is a strong agreement among different methods. Therefore, in this paper, we evaluate the agreement between the feature importance ranks associated with the studied classifiers through a case study of 18 software projects and six commonly used classifiers. We find that: 1) The computed feature importance ranks by CA and CS methods do not always strongly agree with each other. 2) The computed feature importance ranks by the studied CA methods exhibit a strong agreement including the features reported at top-1 and top-3 ranks for a given dataset and classifier, while even the commonly used CS methods yield vastly different feature importance ranks. Such findings raise concerns about the stability of conclusions across replicated studies. We further observe that the commonly used defect datasets are rife with feature interactions and these feature interactions impact the computed feature importance ranks of the CS methods (not the CA methods). We demonstrate that removing these feature interactions, even with simple methods like CFS improves agreement between the computed feature importance ranks of CA and CS methods. In light of our findings, we provide guidelines for stakeholders and practitioners when performing model interpretation and directions for future research, e.g., future research is needed to investigate the impact of advanced feature interaction removal methods on computed feature importance ranks of different CS methods.