 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Corrector LSTM
Apr 28, 2024Forecasting methods are affected by data quality issues in two ways: 1. they are hard to predict, and 2. they may affect the model negatively when it is updated with new data. The latter issue is usually addressed by pre-processing the data to remove those issues. An alternative approach has recently been proposed, Corrector LSTM (cLSTM), which is a Read \& Write Machine Learning (RW-ML) algorithm that changes the data while learning to improve its predictions. Despite promising results being reported, cLSTM is computationally expensive, as it uses a meta-learner to monitor the hidden states of the LSTM. We propose a new RW-ML algorithm, Kernel Corrector LSTM (KcLSTM), that replaces the meta-learner of cLSTM with a simpler method: Kernel Smoothing. We empirically evaluate the forecasting accuracy and the training time of the new algorithm and compare it with cLSTM and LSTM. Results indicate that it is able to decrease the training time while maintaining a competitive forecasting accuracy.
On-the-fly Data Augmentation for Forecasting with Deep Learning
Apr 25, 2024



Deep learning approaches are increasingly used to tackle forecasting tasks. A key factor in the successful application of these methods is a large enough training sample size, which is not always available. In these scenarios, synthetic data generation techniques are usually applied to augment the dataset. Data augmentation is typically applied before fitting a model. However, these approaches create a single augmented dataset, potentially limiting their effectiveness. This work introduces OnDAT (On-the-fly Data Augmentation for Time series) to address this issue by applying data augmentation during training and validation. Contrary to traditional methods that create a single, static augmented dataset beforehand, OnDAT performs augmentation on-the-fly. By generating a new augmented dataset on each iteration, the model is exposed to a constantly changing augmented data variations. We hypothesize this process enables a better exploration of the data space, which reduces the potential for overfitting and improves forecasting performance. We validated the proposed approach using a state-of-the-art deep learning forecasting method and 8 benchmark datasets containing a total of 75797 time series. The experiments suggest that OnDAT leads to better forecasting performance than a strategy that applies data augmentation before training as well as a strategy that does not involve data augmentation. The method and experiments are publicly available.
Pastprop-RNN: improved predictions of the future by correcting the past
Jun 25, 2021
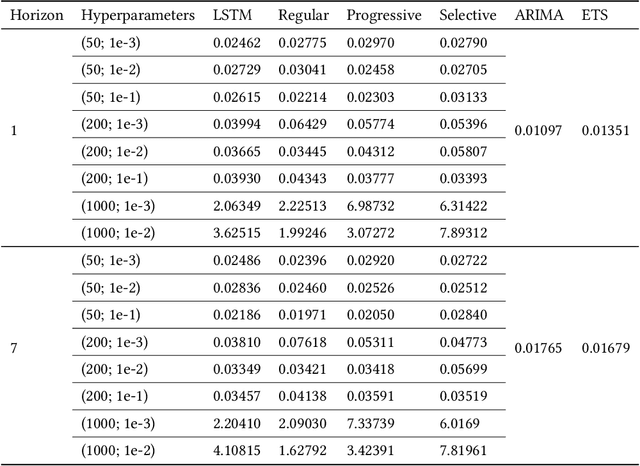
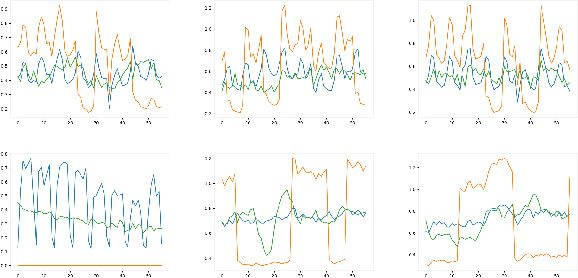
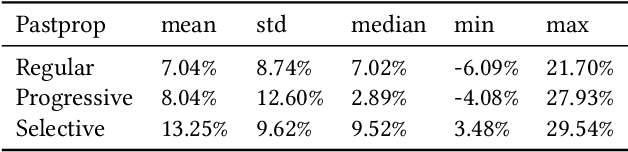
Forecasting accuracy is reliant on the quality of available past data. Data disruptions can adversely affect the quality of the generated model (e.g. unexpected events such as out-of-stock products when forecasting demand). We address this problem by pastcasting: predicting how data should have been in the past to explain the future better. We propose Pastprop-LSTM, a data-centric backpropagation algorithm that assigns part of the responsibility for errors to the training data and changes it accordingly. We test three variants of Pastprop-LSTM on forecasting competition datasets, M4 and M5, plus the Numenta Anomaly Benchmark. Empirical evaluation indicates that the proposed method can improve forecasting accuracy, especially when the prediction errors of standard LSTM are high. It also demonstrates the potential of the algorithm on datasets containing anomalies.