 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Multimodal Integration in the Variational Autoencoder from an Information-Theoretic Perspective
Nov 01, 2024



Human perception is inherently multimodal. We integrate, for instance, visual, proprioceptive and tactile information into one experience. Hence, multimodal learning is of importance for building robotic systems that aim at robustly interacting with the real world. One potential model that has been proposed for multimodal integration is the multimodal variational autoencoder. A variational autoencoder (VAE) consists of two networks, an encoder that maps the data to a stochastic latent space and a decoder that reconstruct this data from an element of this latent space. The multimodal VAE integrates inputs from different modalities at two points in time in the latent space and can thereby be used as a controller for a robotic agent. Here we use this architecture and introduce information-theoretic measures in order to analyze how important the integration of the different modalities are for the reconstruction of the input data. Therefore we calculate two different types of measures, the first type is called single modality error and assesses how important the information from a single modality is for the reconstruction of this modality or all modalities. Secondly, the measures named loss of precision calculate the impact that missing information from only one modality has on the reconstruction of this modality or the whole vector. The VAE is trained via the evidence lower bound, which can be written as a sum of two different terms, namely the reconstruction and the latent loss. The impact of the latent loss can be weighted via an additional variable, which has been introduced to combat posterior collapse. Here we train networks with four different weighting schedules and analyze them with respect to their capabilities for multimodal integration.
Sensorimotor representation learning for an "active self" in robots: A model survey
Nov 25, 2020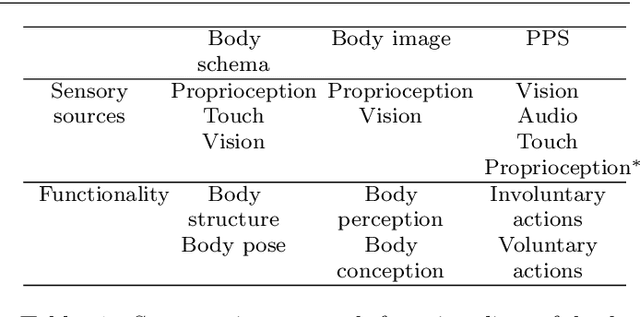

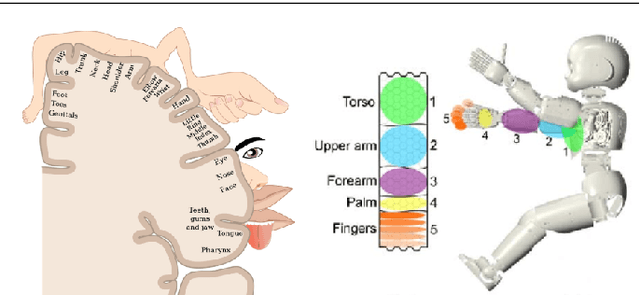
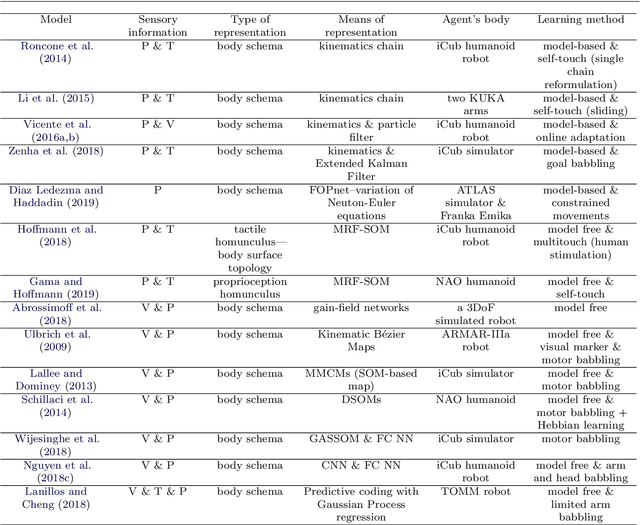
Safe human-robot interactions require robots to be able to learn how to behave appropriately in \sout{humans' world} \rev{spaces populated by people} and thus to cope with the challenges posed by our dynamic and unstructured environment, rather than being provided a rigid set of rules for operations. In humans, these capabilities are thought to be related to our ability to perceive our body in space, sensing the location of our limbs during movement, being aware of other objects and agents, and controlling our body parts to interact with them intentionally. Toward the next generation of robots with bio-inspired capacities, in this paper, we first review the developmental processes of underlying mechanisms of these abilities: The sensory representations of body schema, peripersonal space, and the active self in humans. Second, we provide a survey of robotics models of these sensory representations and robotics models of the self; and we compare these models with the human counterparts. Finally, we analyse what is missing from these robotics models and propose a theoretical computational framework, which aims to allow the emergence of the sense of self in artificial agents by developing sensory representations through self-exploration.