 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Prompting Small Language Models for Privacy-Sensitive Clinical Information Extraction
May 05, 2026Clinical named entity recognition from dental progress notes is challenging because documentation is highly unstructured, domain-specific, and often privacy-sensitive. We developed a locally deployable framework that enables small language models to self-generate, verify, refine, and evaluate entity-specific prompts for extracting multiple clinical entities from dental notes. Using 1,200 annotated notes, we evaluated candidate open-weight models with multi-prompt ensemble inference and further adapted selected models using QLoRA-based supervised fine-tuning and direct preference optimization. Model performance varied substantially, highlighting the need for task-specific evaluation rather than reliance on generic benchmarks. Qwen2.5-14B-Instruct achieved the strongest baseline performance. After DPO, Qwen2.5-14B-Instruct and Llama-3.1-8B-Instruct achieved micro/macro F1 scores of 0.864/0.837 and 0.806/0.797, respectively. These findings suggest that automated prompt optimization combined with lightweight preference-based post-training can support scalable clinical information extraction using locally deployed small language models.
Artificial Intelligence in Extracting Diagnostic Data from Dental Records
Jul 23, 2024This research addresses the issue of missing structured data in dental records by extracting diagnostic information from unstructured text. The updated periodontology classification system's complexity has increased incomplete or missing structured diagnoses. To tackle this, we use advanced AI and NLP methods, leveraging GPT-4 to generate synthetic notes for fine-tuning a RoBERTa model. This significantly enhances the model's ability to understand medical and dental language. We evaluated the model using 120 randomly selected clinical notes from two datasets, demonstrating its improved diagnostic extraction accuracy. The results showed high accuracy in diagnosing periodontal status, stage, and grade, with Site 1 scoring 0.99 and Site 2 scoring 0.98. In the subtype category, Site 2 achieved perfect scores, outperforming Site 1. This method enhances extraction accuracy and broadens its use across dental contexts. The study underscores AI and NLP's transformative impact on healthcare delivery and management. Integrating AI and NLP technologies enhances documentation and simplifies administrative tasks by precisely extracting complex clinical information. This approach effectively addresses challenges in dental diagnostics. Using synthetic training data from LLMs optimizes the training process, improving accuracy and efficiency in identifying periodontal diagnoses from clinical notes. This innovative method holds promise for broader healthcare applications, potentially improving patient care quality.
Robust Privacy Amidst Innovation with Large Language Models Through a Critical Assessment of the Risks
Jul 23, 2024


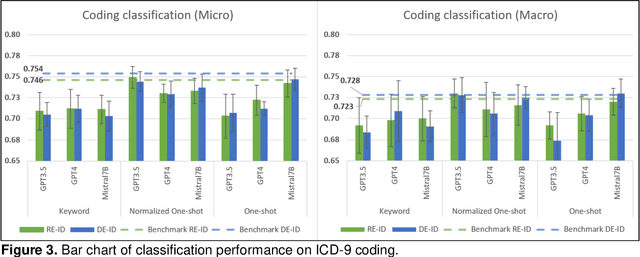
This study examines integrating EHRs and NLP with large language models (LLMs) to improve healthcare data management and patient care. It focuses on using advanced models to create secure, HIPAA-compliant synthetic patient notes for biomedical research. The study used de-identified and re-identified MIMIC III datasets with GPT-3.5, GPT-4, and Mistral 7B to generate synthetic notes. Text generation employed templates and keyword extraction for contextually relevant notes, with one-shot generation for comparison. Privacy assessment checked PHI occurrence, while text utility was tested using an ICD-9 coding task. Text quality was evaluated with ROUGE and cosine similarity metrics to measure semantic similarity with source notes. Analysis of PHI occurrence and text utility via the ICD-9 coding task showed that the keyword-based method had low risk and good performance. One-shot generation showed the highest PHI exposure and PHI co-occurrence, especially in geographic location and date categories. The Normalized One-shot method achieved the highest classification accuracy. Privacy analysis revealed a critical balance between data utility and privacy protection, influencing future data use and sharing. Re-identified data consistently outperformed de-identified data. This study demonstrates the effectiveness of keyword-based methods in generating privacy-protecting synthetic clinical notes that retain data usability, potentially transforming clinical data-sharing practices. The superior performance of re-identified over de-identified data suggests a shift towards methods that enhance utility and privacy by using dummy PHIs to perplex privacy attacks.
De-identification is not always enough
Jan 31, 2024For sharing privacy-sensitive data, de-identification is commonly regarded as adequate for safeguarding privacy. Synthetic data is also being considered as a privacy-preserving alternative. Recent successes with numerical and tabular data generative models and the breakthroughs in large generative language models raise the question of whether synthetically generated clinical notes could be a viable alternative to real notes for research purposes. In this work, we demonstrated that (i) de-identification of real clinical notes does not protect records against a membership inference attack, (ii) proposed a novel approach to generate synthetic clinical notes using the current state-of-the-art large language models, (iii) evaluated the performance of the synthetically generated notes in a clinical domain task, and (iv) proposed a way to mount a membership inference attack where the target model is trained with synthetic data. We observed that when synthetically generated notes closely match the performance of real data, they also exhibit similar privacy concerns to the real data. Whether other approaches to synthetically generated clinical notes could offer better trade-offs and become a better alternative to sensitive real notes warrants further investigation.
Extracting periodontitis diagnosis in clinical notes with RoBERTa and regular expression
Nov 17, 2023This study aimed to utilize text processing and natural language processing (NLP) models to mine clinical notes for the diagnosis of periodontitis and to evaluate the performance of a named entity recognition (NER) model on different regular expression (RE) methods. Two complexity levels of RE methods were used to extract and generate the training data. The SpaCy package and RoBERTa transformer models were used to build the NER model and evaluate its performance with the manual-labeled gold standards. The comparison of the RE methods with the gold standard showed that as the complexity increased in the RE algorithms, the F1 score increased from 0.3-0.4 to around 0.9. The NER models demonstrated excellent predictions, with the simple RE method showing 0.84-0.92 in the evaluation metrics, and the advanced and combined RE method demonstrating 0.95-0.99 in the evaluation. This study provided an example of the benefit of combining NER methods and NLP models in extracting target information from free-text to structured data and fulfilling the need for missing diagnoses from unstructured notes.
Use GPT-J Prompt Generation with RoBERTa for NER Models on Diagnosis Extraction of Periodontal Diagnosis from Electronic Dental Records
Nov 17, 2023



This study explored the usability of prompt generation on named entity recognition (NER) tasks and the performance in different settings of the prompt. The prompt generation by GPT-J models was utilized to directly test the gold standard as well as to generate the seed and further fed to the RoBERTa model with the spaCy package. In the direct test, a lower ratio of negative examples with higher numbers of examples in prompt achieved the best results with a F1 score of 0.72. The performance revealed consistency, 0.92-0.97 in the F1 score, in all settings after training with the RoBERTa model. The study highlighted the importance of seed quality rather than quantity in feeding NER models. This research reports on an efficient and accurate way to mine clinical notes for periodontal diagnoses, allowing researchers to easily and quickly build a NER model with the prompt generation approach.