 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Privacy Amidst Innovation with Large Language Models Through a Critical Assessment of the Risks
Paper and Code
Jul 23, 2024


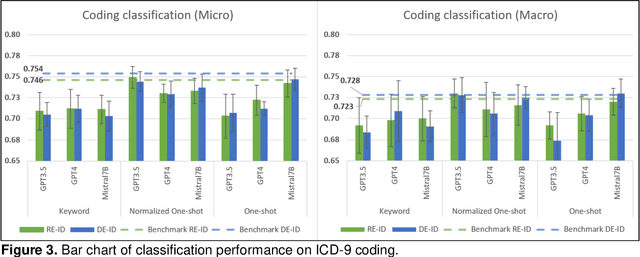
This study examines integrating EHRs and NLP with large language models (LLMs) to improve healthcare data management and patient care. It focuses on using advanced models to create secure, HIPAA-compliant synthetic patient notes for biomedical research. The study used de-identified and re-identified MIMIC III datasets with GPT-3.5, GPT-4, and Mistral 7B to generate synthetic notes. Text generation employed templates and keyword extraction for contextually relevant notes, with one-shot generation for comparison. Privacy assessment checked PHI occurrence, while text utility was tested using an ICD-9 coding task. Text quality was evaluated with ROUGE and cosine similarity metrics to measure semantic similarity with source notes. Analysis of PHI occurrence and text utility via the ICD-9 coding task showed that the keyword-based method had low risk and good performance. One-shot generation showed the highest PHI exposure and PHI co-occurrence, especially in geographic location and date categories. The Normalized One-shot method achieved the highest classification accuracy. Privacy analysis revealed a critical balance between data utility and privacy protection, influencing future data use and sharing. Re-identified data consistently outperformed de-identified data. This study demonstrates the effectiveness of keyword-based methods in generating privacy-protecting synthetic clinical notes that retain data usability, potentially transforming clinical data-sharing practices. The superior performance of re-identified over de-identified data suggests a shift towards methods that enhance utility and privacy by using dummy PHIs to perplex privacy attacks.