 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dual-Pixel Alignment for Defocus Deblurring
Apr 26, 2022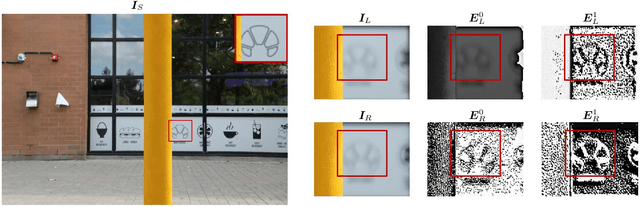
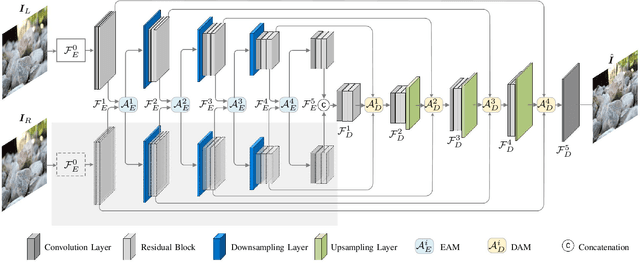
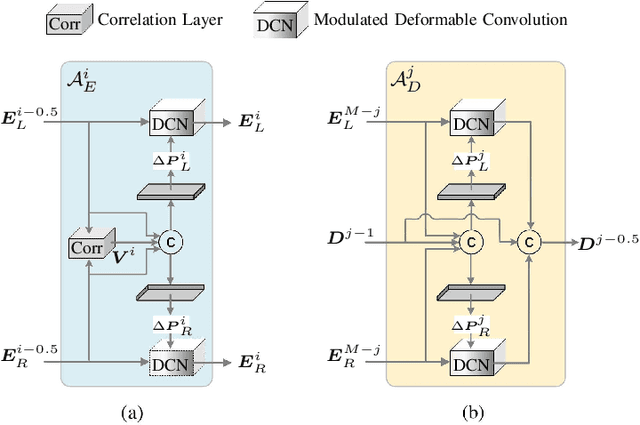

It is a challenging task to recover all-in-focus image from a single defocus blurry image in real-world applications. On many modern cameras, dual-pixel (DP) sensors create two-image views, based on which stereo information can be exploited to benefit defocus deblurring. Despite existing DP defocus deblurring methods achieving impressive results, they directly take naive concatenation of DP views as input, while neglecting the disparity between left and right views in the regions out of camera's depth of field (DoF). In this work, we propose a Dual-Pixel Alignment Network (DPANet) for defocus deblurring. Generally, DPANet is an encoder-decoder with skip-connections, where two branches with shared parameters in the encoder are employed to extract and align deep features from left and right views, and one decoder is adopted to fuse aligned features for predicting the all-in-focus image. Due to that DP views suffer from different blur amounts, it is not trivial to align left and right views. To this end, we propose novel encoder alignment module (EAM) and decoder alignment module (DAM). In particular, a correlation layer is suggested in EAM to measure the disparity between DP views, whose deep features can then be accordingly aligned using deformable convolutions. And DAM can further enhance the alignment of skip-connected features from encoder and deep features in decoder. By introducing several EAMs and DAMs, DP views in DPANet can be well aligned for better predicting latent all-in-focus image. Experimental results on real-world datasets show that our DPANet is notably superior to state-of-the-art deblurring methods in reducing defocus blur while recovering visually plausible sharp structures and textures.
Two-Stage Single Image Reflection Removal with Reflection-Aware Guidance
Dec 02, 2020
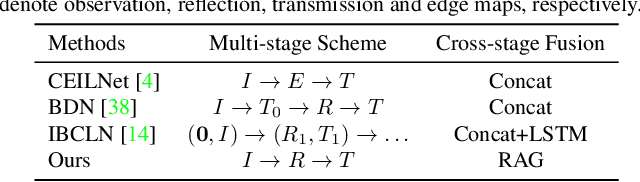
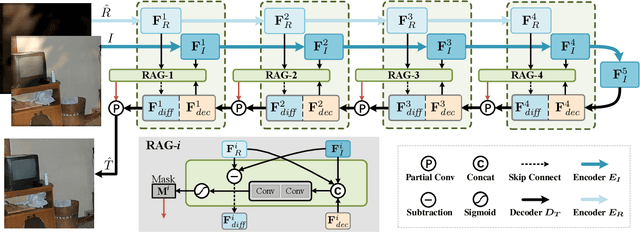
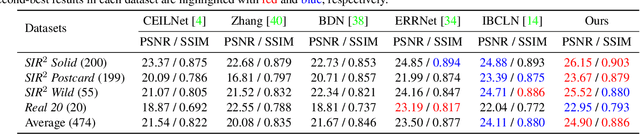
Removing undesired reflection from an image captured through a glass surface is a very challenging problem with many practical application scenarios. For improving reflection removal, cascaded deep models have been usually adopted to estimate the transmission in a progressive manner. However, most existing methods are still limited in exploiting the result in prior stage for guiding transmission estimation. In this paper, we present a novel two-stage network with reflection-aware guidance (RAGNet) for single image reflection removal (SIRR). To be specific, the reflection layer is firstly estimated due to that it generally is much simpler and is relatively easier to estimate. Reflectionaware guidance (RAG) module is then elaborated for better exploiting the estimated reflection in predicting transmission layer. By incorporating feature maps from the estimated reflection and observation, RAG can be used (i) to mitigate the effect of reflection from the observation, and (ii) to generate mask in partial convolution for mitigating the effect of deviating from linear combination hypothesis. A dedicated mask loss is further presented for reconciling the contributions of encoder and decoder features. Experiments on five commonly used datasets demonstrate the quantitative and qualitative superiority of our RAGNet in comparison to the state-of-the-art SIRR methods. The source code and pre-trained model are available at https://github.com/liyucs/RAGNet.