 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering-friendly Representation Learning via Instance Discrimination and Feature Decorrelation
May 31, 2021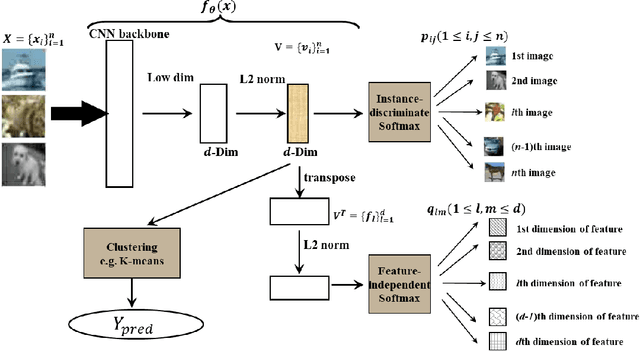
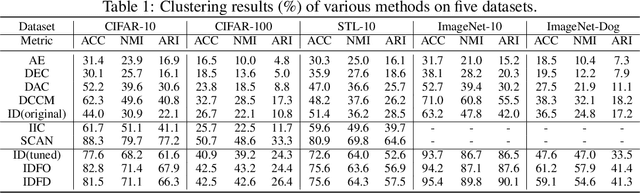

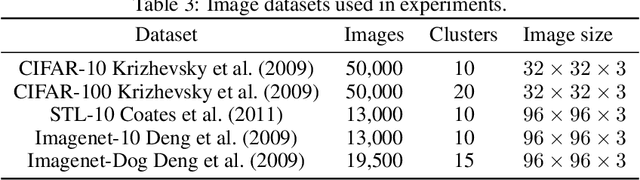
Clustering is one of the most fundamental tasks in machine learning. Recently, deep clustering has become a major trend in clustering techniques. Representation learning often plays an important role in the effectiveness of deep clustering, and thus can be a principal cause of performance degradation. In this paper, we propose a clustering-friendly representation learning method using instance discrimination and feature decorrelation. Our deep-learning-based representation learning method is motivated by the properties of classical spectral clustering. Instance discrimination learns similarities among data and feature decorrelation removes redundant correlation among features. We utilize an instance discrimination method in which learning individual instance classes leads to learning similarity among instances. Through detailed experiments and examination, we show that the approach can be adapted to learning a latent space for clustering. We design novel softmax-formulated decorrelation constraints for learning. In evaluations of image clustering using CIFAR-10 and ImageNet-10, our method achieves accuracy of 81.5% and 95.4%, respectively. We also show that the softmax-formulated constraints are compatible with various neural networks.
Investigating Critical Risk Factors in Liver Cancer Prediction
Feb 03, 2021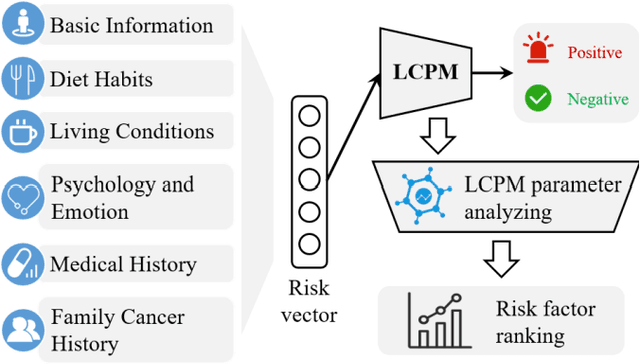

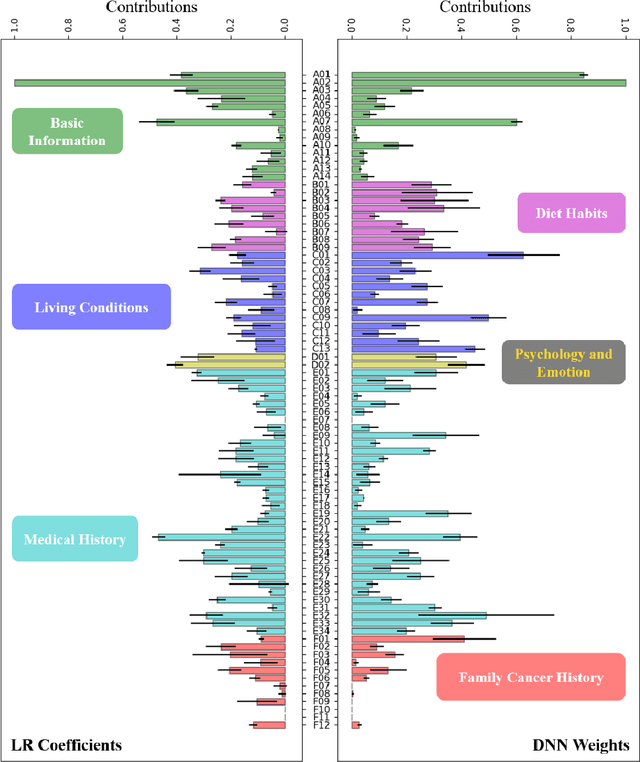
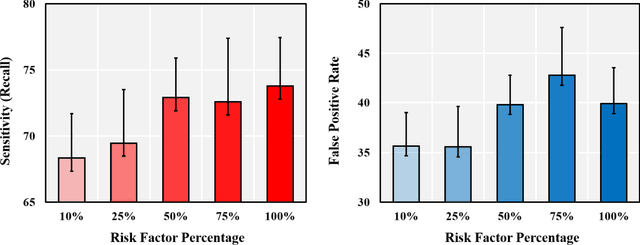
We exploit liver cancer prediction model using machine learning algorithms based on epidemiological data of over 55 thousand peoples from 2014 to the present. The best performance is an AUC of 0.71. We analyzed model parameters to investigate critical risk factors that contribute the most to prediction.
RDEC: Integrating Regularization into Deep Embedded Clustering for Imbalanced Datasets
Dec 06, 2018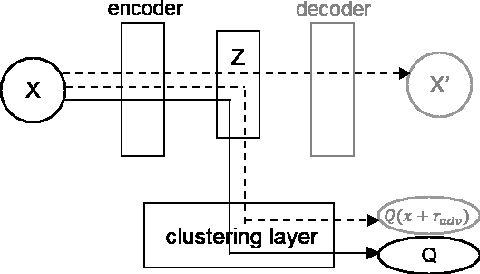
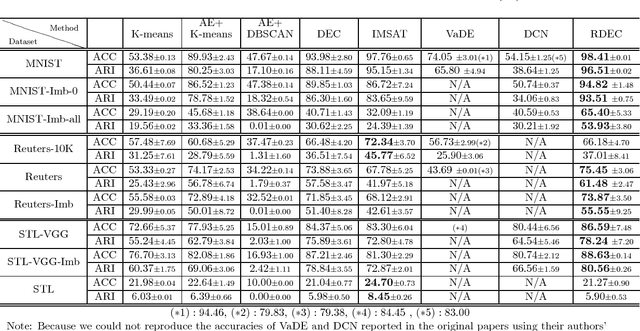
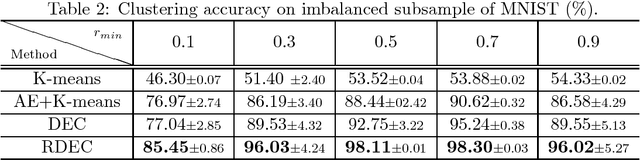
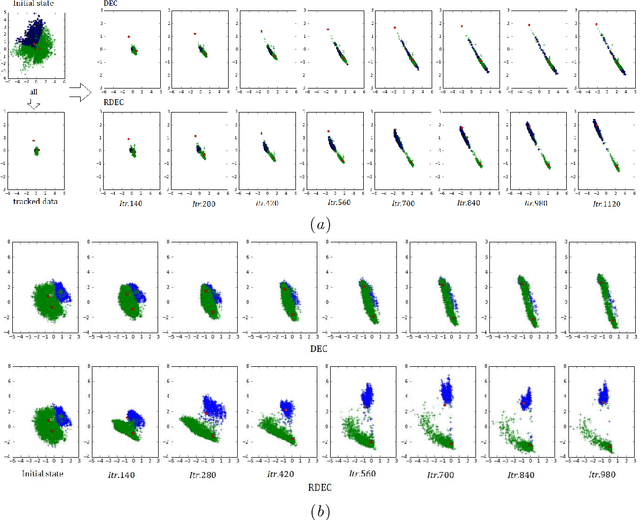
Clustering is a fundamental machine learning task and can be used in many applications. With the development of deep neural networks (DNNs), combining techniques from DNNs with clustering has become a new research direction and achieved some success. However, few studies have focused on the imbalanced-data problem which commonly occurs in real-world applications. In this paper, we propose a clustering method, regularized deep embedding clustering (RDEC), that integrates virtual adversarial training (VAT), a network regularization technique, with a clustering method called deep embedding clustering (DEC). DEC optimizes cluster assignments by pushing data more densely around centroids in latent space, but it is sometimes sensitive to the initial location of centroids, especially in the case of imbalanced data, where the minor class has less chance to be assigned a good centroid. RDEC introduces regularization using VAT to ensure the model's robustness to local perturbations of data. VAT pushes data that are similar in the original space closer together in the latent space, bunching together data from minor classes and thereby facilitating cluster identification by RDEC. Combining the advantages of DEC and VAT, RDEC attains state-of-the-art performance on both balanced and imbalanced benchmark/real-world datasets. For example, accuracies are as high as 98.41% on MNIST dataset and 85.45% on a highly imbalanced dataset derived from the MNIST, which is nearly 8% higher than the current best result.
* 16 pages, 6 figures, accepted by ACML2018