 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Distance Measurement Method for Unsupervised Multivariate Time Series Similarity Retrieval
Mar 13, 2026We propose the Deep Distance Measurement Method (DDMM) to improve retrieval accuracy in unsupervised multivariate time series similarity retrieval. DDMM enables learning of minute differences within states in the entire time series and thereby recognition of minute differences between states, which are of interest to users in industrial plants. To achieve this, DDMM uses a learning algorithm that assigns a weight to each pair of an anchor and a positive sample, arbitrarily sampled from the entire time series, based on the Euclidean distance within the pair and learns the differences within the pairs weighted by the weights. This algorithm allows both learning minute differences within states and sampling pairs from the entire time series. Our empirical studies showed that DDMM significantly outperformed state-of-the-art time series representation learning methods on the Pulp-and-paper mill dataset and demonstrated the effectiveness of DDMM in industrial plants. Furthermore, we showed that accuracy can be further improved by linking DDMM with existing feature extraction methods through experiments with the combined model.
* Workshop of Artificial Intelligence for Time Series Analysis (AI4TS): Theory, Algorithms, and Applications at 2025 IEEE International Conference on Data Mining (ICDM), 2025
Anomaly Detection for Multivariate Time Series on Large-scale Fluid Handling Plant Using Two-stage Autoencoder
May 20, 2022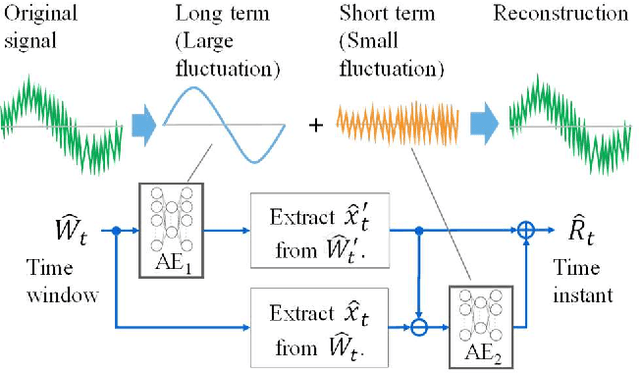

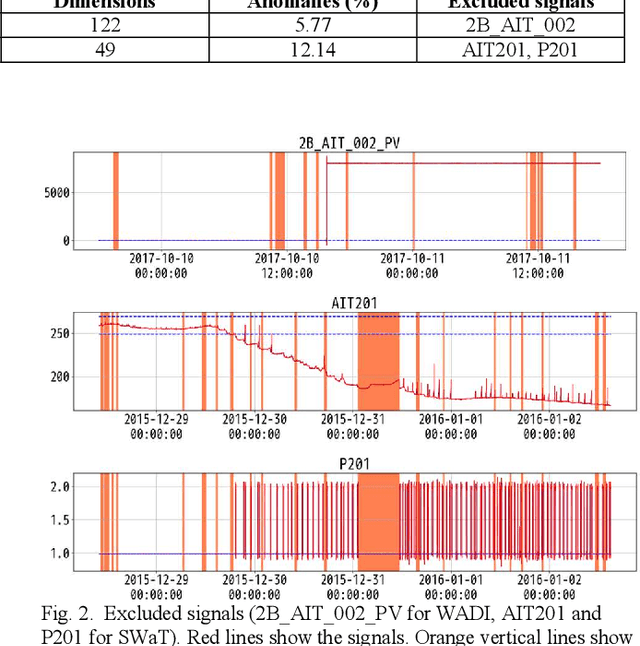
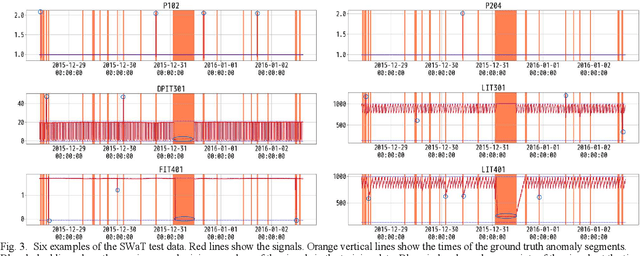
This paper focuses on anomaly detection for multivariate time series data in large-scale fluid handling plants with dynamic components, such as power generation, water treatment, and chemical plants, where signals from various physical phenomena are observed simultaneously. In these plants, the need for anomaly detection techniques is increasing in order to reduce the cost of operation and maintenance, in view of a decline in the number of skilled engineers and a shortage of manpower. However, considering the complex behavior of high-dimensional signals and the demand for interpretability, the techniques constitute a major challenge. We introduce a Two-Stage AutoEncoder (TSAE) as an anomaly detection method suitable for such plants. This is a simple autoencoder architecture that makes anomaly detection more interpretable and more accurate, in which based on the premise that plant signals can be separated into two behaviors that have almost no correlation with each other, the signals are separated into long-term and short-term components in a stepwise manner, and the two components are trained independently to improve the inference capability for normal signals. Through experiments on two publicly available datasets of water treatment systems, we have confirmed the high detection performance, the validity of the premise, and that the model behavior was as intended, i.e., the technical effectiveness of TSAE.
* The 2nd Workshop on Large-scale Industrial Time Series Analysis at the 21st IEEE International Conference on Data Mining (ICDM), 2021
Clustering-friendly Representation Learning via Instance Discrimination and Feature Decorrelation
May 31, 2021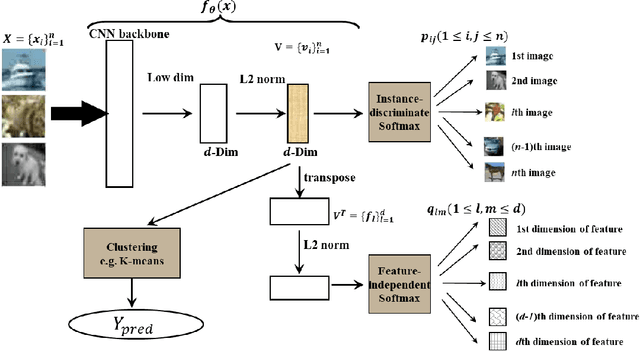
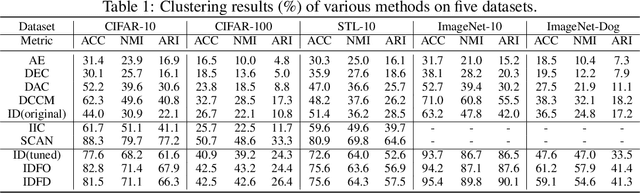

Clustering is one of the most fundamental tasks in machine learning. Recently, deep clustering has become a major trend in clustering techniques. Representation learning often plays an important role in the effectiveness of deep clustering, and thus can be a principal cause of performance degradation. In this paper, we propose a clustering-friendly representation learning method using instance discrimination and feature decorrelation. Our deep-learning-based representation learning method is motivated by the properties of classical spectral clustering. Instance discrimination learns similarities among data and feature decorrelation removes redundant correlation among features. We utilize an instance discrimination method in which learning individual instance classes leads to learning similarity among instances. Through detailed experiments and examination, we show that the approach can be adapted to learning a latent space for clustering. We design novel softmax-formulated decorrelation constraints for learning. In evaluations of image clustering using CIFAR-10 and ImageNet-10, our method achieves accuracy of 81.5% and 95.4%, respectively. We also show that the softmax-formulated constraints are compatible with various neural networks.
RDEC: Integrating Regularization into Deep Embedded Clustering for Imbalanced Datasets
Dec 06, 2018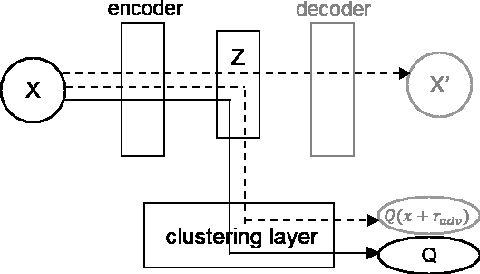
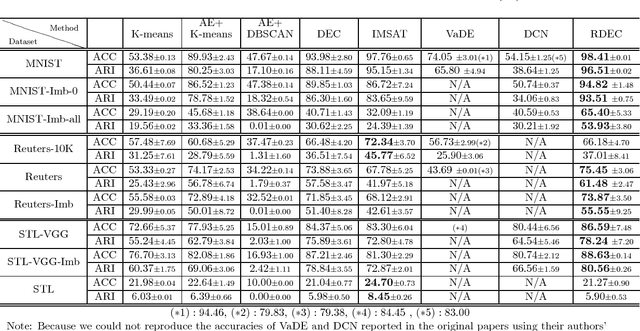
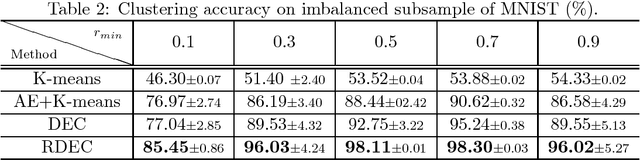
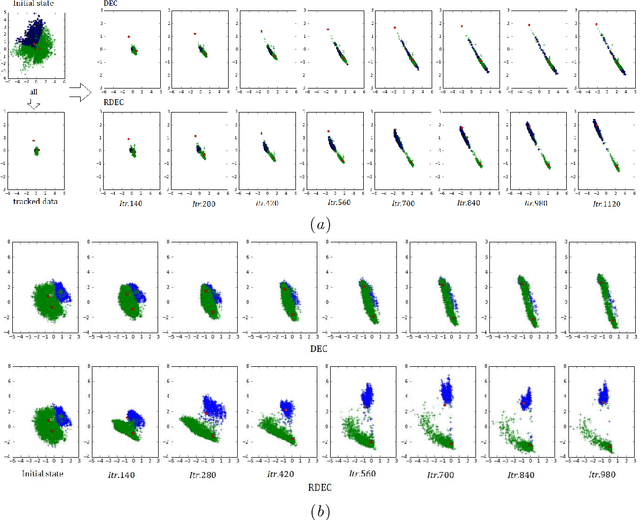
Clustering is a fundamental machine learning task and can be used in many applications. With the development of deep neural networks (DNNs), combining techniques from DNNs with clustering has become a new research direction and achieved some success. However, few studies have focused on the imbalanced-data problem which commonly occurs in real-world applications. In this paper, we propose a clustering method, regularized deep embedding clustering (RDEC), that integrates virtual adversarial training (VAT), a network regularization technique, with a clustering method called deep embedding clustering (DEC). DEC optimizes cluster assignments by pushing data more densely around centroids in latent space, but it is sometimes sensitive to the initial location of centroids, especially in the case of imbalanced data, where the minor class has less chance to be assigned a good centroid. RDEC introduces regularization using VAT to ensure the model's robustness to local perturbations of data. VAT pushes data that are similar in the original space closer together in the latent space, bunching together data from minor classes and thereby facilitating cluster identification by RDEC. Combining the advantages of DEC and VAT, RDEC attains state-of-the-art performance on both balanced and imbalanced benchmark/real-world datasets. For example, accuracies are as high as 98.41% on MNIST dataset and 85.45% on a highly imbalanced dataset derived from the MNIST, which is nearly 8% higher than the current best result.
* 16 pages, 6 figures, accepted by ACML2018